
Large-scale Model 핵심 기술: Architecture, Norm, Positional Encoding
Published:
Large-scale Model에는 학습 안정성, 메모리 효율성, 긴 컨텍스트 처리 등을 위한 다양한 핵심 기술들이 포함되어 있다. 본 리포트는 다양한 최신 LLM에서 널리 채택된 Architecture & Norm과 Positional Encoding & Attention 기술들을 정리한다.
핵심 목표
본 리포트에서 다루는 주요 내용은 다음과 같다.
- Architecture & Norm: Large-scale Model의 일반적인 아키텍처 구조, RMSNorm, SwiGLU, Pre-Norm 등 모델의 학습 안정성과 효율성을 결정하는 핵심 설계 선택
- Positional Encoding: RoPE, mRoPE 등 long context 처리를 위한 위치 인코딩 기술
- Attention: FlashAttention, GQA 등 attention 연산의 메모리 효율성을 위한 기술
각 기술의 수학적 배경, 알고리즘적 세부사항, 그리고 실제 모델에서의 채택 사례를 포함하여, Large-scale Model의 기술적 토대를 이해할 수 있도록 구성했다.
1. Architecture & Norm
1.1 Large-scale Model의 일반적인 아키텍처
Large-scale Language Model은 기본적으로 Transformer 아키텍처를 기반으로 하며, 대부분 Decoder-only 구조를 채택한다. 이는 GPT 시리즈부터 시작하여 Llama, Gemma, Qwen 등 최신 모델들까지 이어지는 표준 구조다.
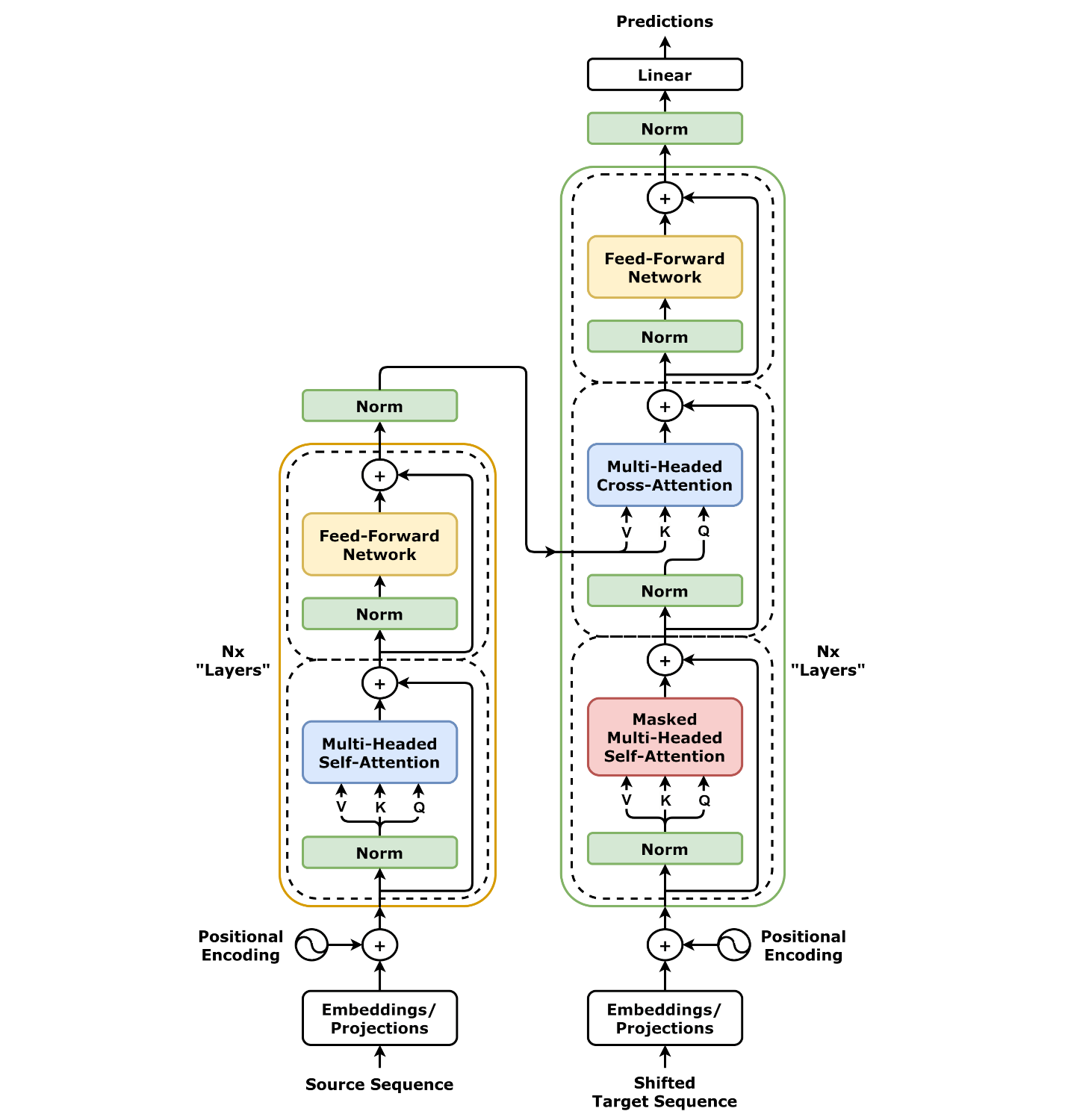
Transformer의 기본 구성 요소
Transformer는 다음과 같은 핵심 구성 요소로 이루어져 있다:
- Multi-Head Self-Attention: 입력 시퀀스 내의 모든 토큰 간의 관계를 학습하는 메커니즘
- Feed-Forward Network (FFN): 각 위치에서 비선형 변환을 수행하는 2-layer MLP
- Residual Connection: 각 sub-layer 주변에 추가되어 gradient flow를 개선
- Layer Normalization: 각 layer의 입력을 정규화하여 학습 안정성 향상
- Positional Encoding: 토큰의 위치 정보를 인코딩
Decoder-only 구조
대부분의 최신 LLM은 Decoder-only 구조를 사용한다. 이는 Encoder-Decoder 구조(BERT, T5 등)와 달리, Encoder 없이 Decoder만으로 구성된다.
Decoder-only 구조의 특징은 다음과 같다.
- Autoregressive Generation: 이전 토큰들을 기반으로 다음 토큰을 생성
- Causal Masking: Attention에서 미래 토큰을 보지 못하도록 마스킹
- 단방향 정보 흐름: 왼쪽에서 오른쪽으로 정보가 흐르는 구조
Decoder Block의 구조
각 Decoder block은 다음과 같이 구성된다.
x → LayerNorm → Multi-Head Attention → Residual → LayerNorm → FFN → Residual → x'
- Pre-Norm 구조: LayerNorm이 attention과 FFN 이전에 적용됨 (최신 모델의 표준)
- Residual Connection: 각 sub-layer의 입력과 출력을 더하여 gradient flow 개선
- FFN: SwiGLU 활성화 함수를 사용하는 2-layer MLP
전체 모델 아키텍처
여러 개의 Decoder block이 쌓여서 전체 모델을 구성한다. 일반적인 Large-scale Model의 전체 구조는 다음과 같다.
Input Tokens
↓
Token Embedding + Positional Encoding (RoPE)
↓
Decoder Block 1
↓
Decoder Block 2
↓
...
↓
Decoder Block N (예: N=32, 40, 80 등)
↓
Final LayerNorm
↓
Output Projection (LM Head)
↓
Output Logits
주요 구성 요소
- Token Embedding: 입력 토큰을 임베딩 벡터로 변환 (vocabulary size × embedding dimension)
- Positional Encoding: RoPE를 사용하여 위치 정보를 인코딩 (임베딩에 직접 적용)
- N개의 Decoder Blocks: 동일한 구조의 블록이 여러 개 쌓임
- Final LayerNorm: 마지막 블록의 출력을 정규화
- Output Projection: 임베딩 차원을 vocabulary size로 projection하여 다음 토큰 확률 예측
이러한 구조에서 각 블록은 이전 블록의 출력을 입력으로 받아 점진적으로 추상화된 표현을 학습하며, 최종적으로 다음 토큰을 예측하기 위한 정보를 생성한다.
Large-scale Model에서 아키텍처 설계 선택은 학습 안정성, 추론 효율성, 그리고 최종 성능에 직접적인 영향을 미친다. 예를 들어 아래와 같은 선택들이 모델의 성능과 효율성을 결정하는 핵심 요소가 된다.
- Normalization 방식 (RMSNorm vs LayerNorm): 학습 속도와 메모리 효율성
- Activation Function (SwiGLU vs ReLU/GELU): 표현력과 gradient flow
- Normalization 위치 (Pre-Norm vs Post-Norm): 깊은 네트워크에서의 학습 안정성
1.2 LayerNorm and RMSNorm
LayerNorm
LayerNorm은 Transformer 아키텍처의 핵심 구성 요소로, 각 layer의 출력을 정규화하여 학습 안정성을 향상시킨다. 여기서 ‘layer’는 Transformer의 각 sub-layer(Attention, FFN 등)를 의미하며, 전체 모델은 이러한 layer들이 여러 개 쌓여서 구성된다. LayerNorm은 입력 벡터의 평균을 제거하고 분산을 정규화하는 과정을 거친다.
LayerNorm의 수식
\[\text{LayerNorm}(x) = \gamma \odot \frac{x - \mu}{\sigma} + \beta\]- $x \in \mathbb{R}^d$: 입력 벡터
- $\mu = \frac{1}{d}\sum_{i=1}^{d} x_i$: 평균
- $\sigma = \sqrt{\frac{1}{d}\sum_{i=1}^{d} (x_i - \mu)^2}$: 표준편차
- $\gamma, \beta \in \mathbb{R}^d$: 학습 가능한 scale과 shift 파라미터
- $\odot$: element-wise 곱셈
LayerNorm은 평균 제거와 분산 정규화를 모두 수행하여, 각 layer의 입력 분포를 안정화시킨다.
BatchNorm과의 차이
BatchNorm (Batch Normalization)은 computer vision 분야에서 널리 사용되는 정규화 기법으로, 배치 차원과 공간 차원에 대해 정규화를 수행한다. 반면 LayerNorm은 feature 차원에 대해 정규화를 수행한다.
입력 텐서가 $x \in \mathbb{R}^{B \times H \times W \times C}$ (B=batch, H=height, W=width, C=channels) 형태일 때 아래와 같은 차이가 존재한다.
- BatchNorm: 배치와 공간 차원 $(B, H, W)$에 대해 정규화
- 평균: $\mu = \frac{1}{B \cdot H \cdot W}\sum_{b,h,w} x_{b,h,w,c}$ (각 채널 $c$마다 독립적으로 계산)
- 배치 내 다른 샘플들의 통계를 사용
- LayerNorm: feature 차원 $C$에 대해 정규화
- 평균: $\mu = \frac{1}{C}\sum_{c} x_{b,h,w,c}$ (각 위치 $(b,h,w)$마다 독립적으로 계산)
- 같은 샘플 내 feature들 간의 통계를 사용
Transformer에서는 입력이 $x \in \mathbb{R}^{B \times T \times D}$ (B=batch, T=sequence length, D=embedding dimension) 형태인데, LayerNorm은 마지막 차원 $D$에 대해 정규화한다.
- 평균: $\mu = \frac{1}{D}\sum_{d} x_{b,t,d}$ (각 위치 $(b,t)$마다 독립적으로 계산)
개념적으로는 BatchNorm의 경우 배치 내 다른 샘플들의 통계를 사용하므로 배치 크기에 의존적이며, 학습 시 moving average를 사용하여 추론 시에도 안정적인 통계를 유지한다. 하지만 작은 배치 크기에서 성능이 저하되고 batch size=1일 때는 동작하지 않는다. CNN에서는 효과적이지만, 시퀀스 모델(RNN, Transformer)에서는 부적합하다.
반면 LayerNorm은 각 샘플을 독립적으로 정규화하므로 배치 크기에 독립적이며, 학습과 추론 시 동일한 방식으로 동작한다. 배치 크기=1에서도 정상 동작하며, 각 토큰/위치를 독립적으로 정규화하여 시퀀스 길이가 달라도 일관된 동작을 보인다. Transformer와 같은 시퀀스 모델에서는 각 샘플의 시퀀스 길이가 다를 수 있고, autoregressive generation 시 배치 크기=1에서도 동작해야 하므로, 배치 독립적인 LayerNorm이 필수적이다.
RMSNorm
RMSNorm (Root Mean Square Layer Normalization)은 LayerNorm의 변형으로, 평균 제거 단계를 생략하고 Root Mean Square만 사용한다.
\[\text{RMSNorm}(x) = \frac{x}{\text{RMS}(x)} \odot \gamma\]- $\text{RMS}(x) = \sqrt{\frac{1}{d}\sum_{i=1}^{d} x_i^2}$: Root Mean Square
RMSNorm은 평균 계산을 생략하므로 LayerNorm보다 계산량이 적다. 특히 대규모 모델에서 이 차이는 누적되어 상당한 성능 향상으로 이어진다. 현재 대부분의 최신 LLM은 RMSNorm을 표준으로 채택하고 있다.
왜 대규모 모델에서 RMSNorm을 선택하는가
- 연산 효율성: 평균 계산 제거로 약 10-15% 속도 향상. LayerNorm은 평균과 분산을 모두 계산해야 하지만, RMSNorm은 RMS만 계산하면 되므로 연산량이 감소한다. 특히 배치 크기가 크고 시퀀스 길이가 긴 경우, 이 차이는 더욱 커진다.
- 메모리 효율성: 중간 값 저장 감소. LayerNorm은 평균 $\mu$를 저장해야 하지만, RMSNorm은 RMS 값만 저장하면 되므로 메모리 사용량이 감소한다.
- 학습 안정성: 실험적으로 큰 모델에서 LayerNorm과 동등하거나 더 나은 성능을 보인다. RMSNorm은 평균 중심화 없이도 충분한 정규화 효과를 제공하며, 일부 연구에서는 더 나은 gradient flow를 보여준다고 보고된다.
1.3 SwiGLU Activation
ReLU와 GELU의 한계
ReLU (Rectified Linear Unit)는 $f(x) = \max(0, x)$로 정의되는 활성화 함수로, 입력이 양수이면 그대로 통과시키고 음수이면 0으로 만든다. ReLU는 간단하고 계산이 빠르지만, 음수 영역에서 항상 0을 출력하므로 이 영역의 gradient가 0이 된다. 학습 과정에서 많은 뉴런의 입력이 음수가 되면, 이 뉴런들은 더 이상 업데이트되지 않는 “dying ReLU” 문제가 발생한다. 특히 깊은 네트워크나 학습률이 높을 때 이 문제가 더 심각해진다.
GELU (Gaussian Error Linear Unit)는 $f(x) = x \cdot \Phi(x)$ (여기서 $\Phi(x)$는 표준 정규분포의 누적분포함수)로 정의되며, ReLU보다 부드러운 곡선을 가진다. GELU는 입력 값이 작을수록 더 작은 값을 출력하고, 입력 값이 클수록 더 큰 값을 출력하는 부드러운 전환을 제공한다. 이는 gradient flow를 개선하지만, 누적분포함수를 계산해야 하므로 ReLU보다 계산 비용이 더 크다. 또한 대규모 모델에서 모든 뉴런에 대해 이러한 계산을 수행하는 것은 상당한 오버헤드가 될 수 있다.
SwiGLU
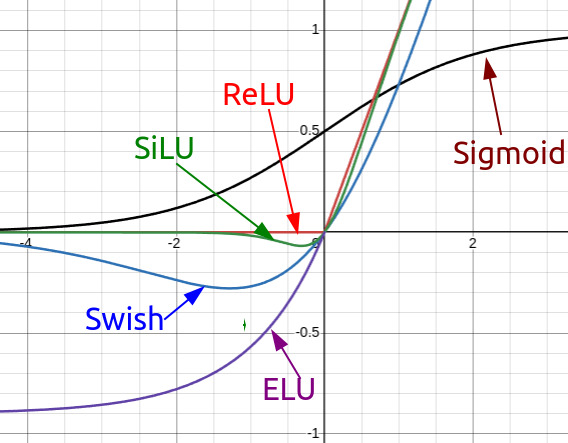
SwiGLU는 Swish 활성화 함수와 Gated Linear Unit (GLU)을 결합한 활성화 함수다. Swish는 단순한 활성화 함수로 $\text{Swish}(x) = x \cdot \text{sigmoid}(x)$로 정의되며, SwiGLU는 이 Swish를 GLU의 gate 메커니즘과 결합한 것이다.
\[\text{SwiGLU}(x) = \text{Swish}(xW + b) \odot (xV + c)\]- $\text{Swish}(x) = x \cdot \text{sigmoid}(x)$: Swish 활성화 함수 (단순한 pointwise 활성화 함수)
- $W, V$: 학습 가능한 가중치 행렬 (두 개의 독립적인 선형 변환)
- $b, c$: bias 벡터
- $\odot$: element-wise 곱셈 (gate 역할)
SwiGLU는 Swish와 달리 두 개의 선형 변환을 사용하며, 하나는 Swish를 거치고 다른 하나는 gate로 사용된다. 이는 단순히 Swish를 적용하는 것과는 다른 구조로, 더 강력한 표현력을 제공한다.
GLU (Gated Linear Unit)의 개념
GLU는 두 개의 선형 변환을 곱하여 gate 메커니즘을 구현한다. 하나의 경로는 활성화 함수를 거치고, 다른 경로는 gate 역할을 하여 정보 흐름을 제어한다. 이는 LSTM의 gate 메커니즘과 유사한 아이디어다.
성능적 이점
- 더 부드러운 gradient: Swish 함수는 ReLU보다 부드러운 곡선을 가지므로 gradient가 더 안정적으로 흐른다. 특히 깊은 네트워크에서 gradient vanishing 문제를 완화한다.
- 더 나은 표현력: Gate 메커니즘을 통해 모델이 어떤 정보를 통과시킬지 학습할 수 있어, 표현력이 향상된다. 실험적으로 같은 파라미터 수에서 더 나은 성능을 보인다.
1.4 Pre-Normalization vs. Post-Normalization
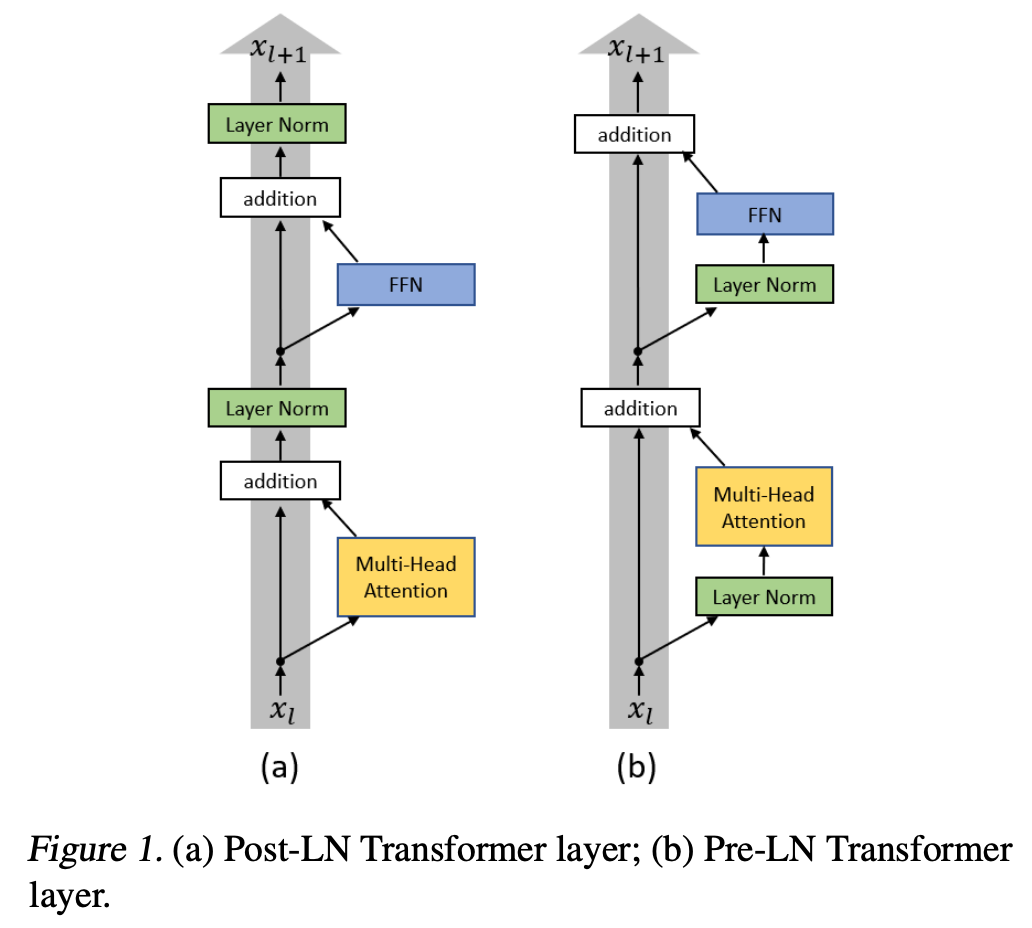
Transformer 아키텍처에서 Normalization의 위치는 모델의 학습 안정성과 성능에 중요한 영향을 미친다. Normalization을 residual connection과 sub-layer(Attention, FFN) 연산의 어느 위치에 배치하느냐에 따라 gradient flow, 학습 속도, 그리고 깊은 네트워크에서의 안정성이 달라진다. Pre-Normalization (Pre-Norm)은 normalization을 sub-layer 연산 전에 적용하고, Post-Normalization (Post-Norm)은 sub-layer 연산 후에 적용한다.
Post-Normalization 구조
Post-Norm은 Transformer의 원래 구조로, attention과 feed-forward 연산 후에 normalization을 적용한다.
\[x_{l+1} = x_l + \text{Norm}(\text{Attention}(x_l))\] \[x_{l+1} = x_l + \text{Norm}(\text{FFN}(x_l))\]여기서 각 sub-layer는 residual connection과 normalization으로 구성된다.
Pre-Normalization 구조
Pre-Norm은 normalization을 attention과 feed-forward 연산 전에 적용한다.
\[x_{l+1} = x_l + \text{Attention}(\text{Norm}(x_l))\] \[x_{l+1} = x_l + \text{FFN}(\text{Norm}(x_l))\]이 구조는 각 sub-layer의 입력을 먼저 정규화한 후 연산을 수행한다.
Gradient Vanishing/Exploding 문제
깊은 네트워크에서 gradient가 layer를 거치면서 급격히 작아지거나 커지는 문제가 발생할 수 있다. Post-Norm 구조에서는 normalization이 residual connection 이후에 적용되므로, gradient가 여러 layer를 거치면서 불안정해질 수 있다.
Pre-Norm의 장점
- 더 안정적인 gradient flow: Normalization이 residual connection 이전에 적용되므로, gradient가 더 직접적으로 흐를 수 있다. 이는 깊은 네트워크에서 특히 중요하다.
- Deep network에서의 학습 안정성: 실험적으로 Pre-Norm은 더 깊은 네트워크에서도 안정적으로 학습할 수 있다. Post-Norm은 깊이가 깊어질수록 학습이 어려워지는 경향이 있지만, Pre-Norm은 이러한 문제가 덜하다.
- 사례: GPT-2는 Post-Norm을 사용했지만, 이후 대부분의 모델은 Pre-Norm을 채택했다. Llama 시리즈, Gemma 시리즈, Qwen 시리즈 등이 Pre-Norm을 사용하며, 최신 모델들인 Qwen3, Gemma3, GLM-4.5도 모두 Pre-Norm 아키텍처를 채택하고 있다. Pre-Norm은 학습 속도와 최종 성능 모두에서 우수한 결과를 보이며, 특히 깊은 네트워크에서의 학습 안정성 때문에 대규모 모델의 표준이 되었다.
2. Positional Encoding
2.1 RoPE (Rotary Positional Embedding)
RoPE (Rotary Position Embedding)는 회전 행렬을 이용하여 상대적 위치 정보를 인코딩하는 방법이다. 절대 위치를 직접 인코딩하는 대신, query와 key 벡터를 회전시켜 상대적 위치 관계를 보존한다.
RoPE는 복소수 평면에서의 회전을 실수 벡터에 적용하기 위해, 임베딩 차원을 2차원 쌍으로 나누어 각 쌍에 대해 회전 행렬을 적용한다. 예를 들어, 임베딩 차원이 $d=8$인 경우, 차원 0-1, 2-3, 4-5, 6-7로 4개의 쌍을 형성한다. 각 쌍은 복소수 평면에서 하나의 복소수로 해석될 수 있으며, 회전 행렬을 통해 위치 정보를 인코딩한다.
RoPE 수식
각 차원 쌍 $(2i, 2i+1)$에 대해 회전 행렬을 적용한다.
\[R_{\Theta, m}^d = \begin{pmatrix} \cos m\theta_i & -\sin m\theta_i \\ \sin m\theta_i & \cos m\theta_i \end{pmatrix}\]- $\theta_i = 10000^{-2i/d}$: 각 차원 쌍 $i$에 대한 기본 주파수 (각도)
- $m$: 토큰의 위치 (sequence 내에서의 절대 위치)
- $d$: 임베딩 차원
동일한 시퀀스 내에서도 차원 쌍에 따라 각도가 달라진다. 예를 들어, $d=128$인 경우 아래와 같다.
- $i=0$: $\theta_0 = 10000^{-0/128} = 1$ (가장 느린 회전)
- $i=1$: $\theta_1 = 10000^{-2/128} \approx 0.86$
- $i=31$: $\theta_{31} = 10000^{-62/128} \approx 0.0001$ (가장 빠른 회전)
이렇게 차원에 따라 다른 주파수를 사용함으로써, 저주파 차원은 긴 거리 관계를, 고주파 차원은 짧은 거리 관계를 인코딩할 수 있다. 토큰 위치 $m$이 증가할수록 회전 각도 $m\theta_i$도 선형적으로 증가한다. 예를 들어, $\theta_i = 1$인 차원 쌍에서
- position $m=0$: 회전 각도 $0 \times 1 = 0$ (회전 없음)
- position $m=1$: 회전 각도 $1 \times 1 = 1$ 라디안
- position $m=2$: 회전 각도 $2 \times 1 = 2$ 라디안
이렇게 각 토큰 위치마다 다른 각도로 회전하므로, 위치 정보가 벡터에 인코딩된다.
Query와 key 벡터에 회전 행렬을 적용하면 아래와 같고,
\[\tilde{q}_m = R_{\Theta, m}^d q_m\] \[\tilde{k}_n = R_{\Theta, n}^d k_n\]여기서 $R_{\Theta, m}^d$는 각 차원 쌍에 대해 독립적으로 적용된다. 예를 들어, $d=4$인 벡터 $q_m = [q_0, q_1, q_2, q_3]^T$에 대해 다음과 같이 적용된다.
- 차원 쌍 (0,1)에 $R_{\Theta, m}^2$ 적용: 회전 행렬을 적용하여 $(\tilde{q}_0, \tilde{q}_1)^T$를 얻는다
- 차원 쌍 (2,3)에 $R_{\Theta, m}^2$ 적용: 회전 행렬을 적용하여 $(\tilde{q}_2, \tilde{q}_3)^T$를 얻는다
수식으로 표현하면 각 차원 쌍 $(i, i+1)$에 대해 \(\begin{pmatrix} \tilde{q}_i \\ \tilde{q}_{i+1} \end{pmatrix} = R_{\Theta, m}^2 \begin{pmatrix} q_i \\ q_{i+1} \end{pmatrix}\)
이렇게 변환된 query와 key의 내적은 상대적 위치 $(m-n)$에만 의존한다.
\[\tilde{q}_m^T \tilde{k}_n = q_m^T R_{\Theta, n-m}^d k_n\]이는 회전 행렬의 성질 $R_{\Theta, m}^T R_{\Theta, n} = R_{\Theta, n-m}$에 의해 보장된다. 따라서 두 토큰의 절대 위치 $m$과 $n$이 아니라, 그 차이 $(m-n)$만이 attention score에 영향을 미친다.
실제 예시
예를 들어, “the cat sat”라는 시퀀스에서
- “the” (위치 $m=0$): 회전 각도 $0 \times \theta_i = 0$
- “cat” (위치 $m=1$): 회전 각도 $1 \times \theta_i = \theta_i$
- “sat” (위치 $m=2$): 회전 각도 $2 \times \theta_i = 2\theta_i$
“the”와 “cat”의 attention score는 상대적 위치 $(1-0)=1$에 의존하고, “the”와 “sat”의 attention score는 상대적 위치 $(2-0)=2$에 의존한다. 이는 “the cat”과 “cat sat”처럼 동일한 상대적 거리를 가진 쌍들이 동일한 attention 패턴을 가질 수 있음을 의미한다.
왜 상대적 위치가 중요한가?
자연어에서 단어의 의미는 절대 위치보다는 다른 단어들과의 상대적 관계에 의해 결정된다. 예를 들어, “the cat sat on the mat”에서 “cat”과 “mat”의 관계는 문장 내에서의 절대 위치보다는 두 단어 사이의 거리와 관계가 더 중요하다. RoPE는 이러한 상대적 위치 관계를 명시적으로 보존한다.
절대 위치 인코딩과의 비교
- Sinusoidal Positional Encoding: 절대 위치를 직접 인코딩하지만, 학습 시 본 적 없는 긴 위치에 대해 extrapolation이 어렵다.
- Learned Positional Embedding: 학습 가능한 위치 임베딩을 사용하지만, 학습 시 사용한 최대 길이를 넘어서면 성능이 급격히 저하된다.
- RoPE: 상대적 위치를 보존하므로, 학습 시 본 적 없는 긴 위치에서도 상대적 관계는 유지된다. 다만 완전한 extrapolation은 어렵고, rescaling 등의 기법이 필요하다.
2.2 mRoPE (Multimodal RoPE)
기존 RoPE는 1D 텍스트 시퀀스에만 적용되며, 이미지나 비디오와 같은 다차원 데이터의 시공간 정보를 인코딩하기 어려운 한계가 존재한다.
mRoPE (Multimodal RoPE)는 이미지와 비디오의 시공간 정보를 인코딩하기 위해 RoPE를 확장한 방법으로 이미지의 경우 높이(Height)와 너비(Width) 차원을, 비디오의 경우 시간(Time), 높이, 너비 차원을 각각 인코딩한다.
Qwen2-VL, Qwen3-VL의 Interleaved-MRoPE
Qwen3-VL에서 제안한 Interleaved-MRoPE는 T, H, W 차원을 분리하지 않고 channel별로 interleave하여 인코딩한다.
기존 mRoPE 방식은 각 차원을 연속적인 블록으로 분할했다.
- Channel 0~42: Time(T) 차원만 encoding
- Channel 43~85: Height(H) 차원만 encoding
- Channel 86~127: Width(W) 차원만 encoding
Interleaved-MRoPE는 다음과 같이 interleave한다.
- Channel 0: Time(T)
- Channel 1: Height(H)
- Channel 2: Width(W)
- Channel 3: Time(T)
- Channel 4: Height(H)
- Channel 5: Width(W)
- …
이렇게 하면 모든 attention head가 시간과 공간 정보의 joint blend를 관찰하게 되어, spatio-temporal 상호작용을 효과적으로 학습할 수 있다.
수식과 구현 세부사항
각 차원에 대해 독립적인 회전 행렬을 적용하되, channel별로 차원을 할당한다.
\[R_{\Theta_T, t}^d, R_{\Theta_H, h}^d, R_{\Theta_W, w}^d\]여기서 각 차원의 기본 주파수 $\Theta_T, \Theta_H, \Theta_W$는 독립적으로 설정될 수 있다.
3. Attention
3.1 FlashAttention
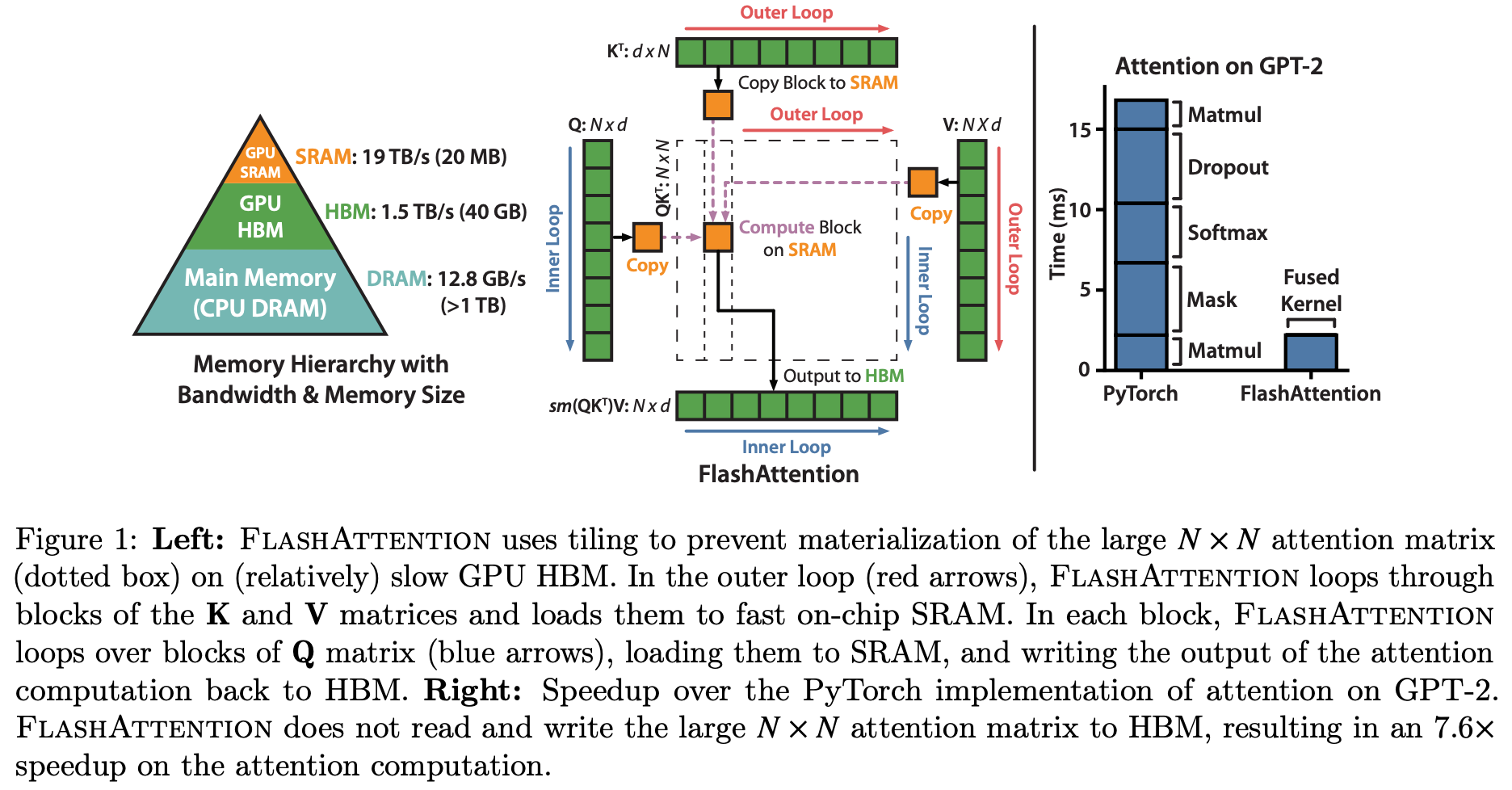
FlashAttention은 표준 attention의 메모리 병목 문제를 해결하기 위해 개발된 최적화 기법으로, tiling, recomputation, 그리고 online softmax 알고리즘을 결합한 CUDA 커널 최적화 기술이다. FlashAttention v1은 forward pass의 메모리 사용량을 $O(N^2)$에서 $O(N)$으로 줄였고, v2는 backward pass까지 최적화하여 전체 학습 과정에서 메모리 효율성을 향상시켰다. 최신 버전인 v3는 다양한 하드웨어에 대한 추가 최적화를 포함하여 더욱 효율적인 attention 연산을 제공한다.
표준 attention 연산은 다음과 같이 수행된다:
\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\]이 과정에서 $QK^T$ 행렬을 메모리에 저장해야 하므로, sequence length가 $N$일 때 $O(N^2)$ 메모리가 필요하다. 긴 시퀀스(예: 32K, 128K)에서는 이 메모리 요구사항이 GPU 메모리를 초과할 수 있다.
FlashAttention은 tiling과 recomputation을 통해 메모리 사용량을 줄인다. 전체 $QK^T$ 행렬을 한 번에 계산하는 대신, 작은 블록(tile) 단위로 나누어 계산하고, backward pass에서 필요할 때 재계산한다.
Online Softmax 알고리즘
FlashAttention은 online softmax 알고리즘을 사용하여, 전체 행렬을 메모리에 저장하지 않고도 softmax를 계산할 수 있다. 이는 streaming 방식으로 최대값과 합을 누적하면서 softmax를 계산하는 방법이다.
FlashAttention v1
- Forward pass 최적화: Tiling을 통해 $O(N^2)$ 메모리를 $O(N)$으로 감소
- Backward pass: 여전히 표준 방식 사용 (gradient 저장 필요)
FlashAttention v2
- Backward pass 최적화: Forward pass에서 저장한 중간 값들을 재사용하여 backward pass도 최적화
- Work partitioning 개선: GPU의 SM(Streaming Multiprocessor) 간 작업 분배를 개선하여 더 나은 병렬화
FlashAttention v3
- 추가 최적화: 다양한 하드웨어(H100, A100 등)에 대한 최적화
- 다양한 하드웨어 지원: 다양한 GPU 아키텍처에 맞춘 커널 최적화
CUDA 커널 최적화 세부사항
FlashAttention은 CUDA 커널을 직접 작성하여 다음과 같은 최적화를 수행한다.
- Shared Memory 활용: GPU의 shared memory를 효율적으로 사용하여 global memory 접근 최소화
- Memory Coalescing: 메모리 접근 패턴을 최적화하여 대역폭 활용 극대화
- Warp-level Primitives: CUDA warp 내에서의 효율적인 연산 수행
메모리 IO 병목 해결 원리
표준 attention은 메모리에서 데이터를 읽고 쓰는 과정에서 병목이 발생한다.
- 데이터를 한 번만 읽고 쓰도록 최적화
- 중간 결과를 shared memory에 저장하여 global memory 접근 최소화
- 결과적으로 메모리 IO를 크게 줄여 전체 속도 향상
3.2 GQA (Grouped Query Attention) & MQA
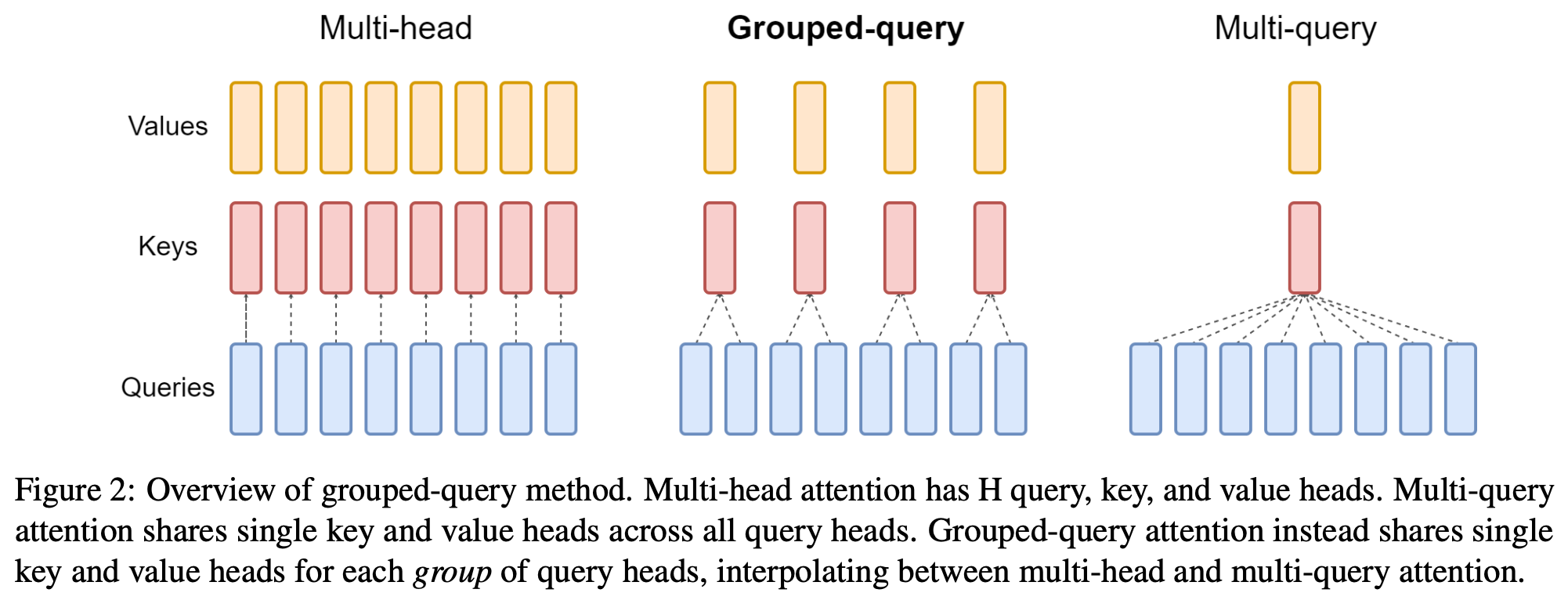
표준 Multi-Head Attention (MHA)에서는 각 head마다 독립적인 K, V를 가지므로, 긴 컨텍스트에서 KV cache의 메모리 사용량이 크게 증가한다. 이를 해결하기 위해 MQA (Multi-Query Attention)와 GQA (Grouped Query Attention)가 제안되었다. 이들은 여러 head가 K, V를 공유함으로써 메모리 사용량을 줄이면서도 추론 속도를 향상시킨다.
\[\text{Memory} = 2 \times N_h \times d_h \times L\]여기서 $N_h$는 head 수, $d_h$는 head dimension, $L$은 sequence length이다. 예를 들어, 32 head, head_dim=128, seq_len=32K인 경우 Memory = 2 × 32 × 128 × 32,768 = 약 268MB (FP16 기준)로, 긴 컨텍스트에서 상당한 메모리 부담이 된다.
MQA (Multi-Query Attention)
\[\text{Memory} = 2 \times d_h \times L\]MQA (Multi-Query Attention)는 모든 head가 하나의 K, V를 공유하는 방식이다. 위 예시에서 Memory = 2 × 128 × 32,768 = 약 8.4MB (FP16 기준)로, 메모리 사용량이 약 32배 감소한다. 이는 추론 속도를 크게 향상시키지만, 모든 head가 동일한 K, V를 사용하므로 표현력이 제한될 수 있다.
실험적으로 MQA는 추론 속도는 크게 향상되지만, 모델 품질 저하와 학습 불안정성 문제가 존재한다. 특히 복잡한 작업이나 긴 컨텍스트에서 성능 저하가 두드러질 수 있다. 이러한 한계 때문에 MQA는 주로 추론 속도가 중요한 특정 응용에서만 사용되며, 일반적인 LLM에서는 GQA가 더 선호된다.
GQA (Grouped Query Attention)
GQA (Grouped Query Attention)는 MQA와 MHA의 중간 형태로, 여러 head가 하나의 K, V 그룹을 공유한다. GQA는 query head를 여러 그룹으로 나누고, 각 그룹이 하나의 key-value head 쌍을 공유하는 방식이다.
\[\text{Memory} = 2 \times N_{kv} \times d_h \times L\]여기서 $N_{kv}$는 KV head 수이고 $N_{kv} < N_h$이다. 예를 들어, 32 head 중 8개의 KV head를 사용하면 MHA 대비 4배 감소하여 Memory = 2 × 8 × 128 × 32,768 = 약 67MB (FP16 기준)가 되고 MQA보다는 더 많은 표현력을 유지한다.
GQA 논문에서는 기존 MHA 체크포인트를 GQA로 변환하는 uptraining 방법을 제안했다. 이 방법은 원래 pre-training compute의 약 5%만 사용하여 기존 모델을 변환할 수 있으며, key-value projection 행렬을 mean-pooling하여 단일 projection 행렬로 만드는 방식이 개별 head 선택이나 랜덤 초기화보다 우수한 성능을 보인다. 실험 결과, GQA는 MHA에 가까운 품질을 유지하면서도 MQA만큼 빠른 추론 속도를 달성한다. 이러한 특성 때문에 Llama 2, Gemma 등 최신 LLM에서 GQA가 표준으로 채택되었다.
수식 비교
- MHA
- $Q_i, K_i, V_i \in \mathbb{R}^{N \times d_k}, \quad i = 1, \ldots, h$
- MQA
- $Q_i \in \mathbb{R}^{N \times d_k}, \quad K, V \in \mathbb{R}^{N \times d_k}, \quad i = 1, \ldots, h$
- GQA
- $Q_i \in \mathbb{R}^{N \times d_k}, \quad K_j, V_j \in \mathbb{R}^{N \times d_k}, \quad i = 1, \ldots, h, \quad j = 1, \ldots, g$
여기서 $g < h$이고, 각 query head는 하나의 KV head 그룹에 매핑된다.
성능-메모리 trade-off
- MHA: 최고 표현력, 최대 메모리
- GQA: 균형잡힌 표현력과 메모리 효율성
- MQA: 최대 메모리 효율, 제한된 표현력
결론
Large-scale Model의 Architecture & Norm과 Positional Encoding & Attention 기술들은 모델의 학습 안정성, 추론 효율성, 그리고 성능에 직접적인 영향을 미친다. Decoder-only Transformer 아키텍처의 전체 구조를 이해하고, 각 구성 요소(RMSNorm, SwiGLU, Pre-Norm, RoPE, FlashAttention, GQA 등)의 역할과 선택 이유를 파악하는 것은 최신 LLM을 이해하고 활용하는 데 도움이 된다.
특히 이러한 기술들이 실제 모델에서 어떻게 결합되어 작동하는지 이해하면, 모델의 동작 원리를 더 깊이 파악할 수 있고, 새로운 모델을 평가하거나 설계할 때도 유용한 기준이 된다.
참고 자료
- Transformer: “Attention Is All You Need” (Vaswani et al., 2017)
- RMSNorm: “Root Mean Square Layer Normalization” (Zhang & Sennrich, 2019)
- SwiGLU: “GLU Variants Improve Transformer” (Shazeer, 2020)
- Pre-Norm: “On Layer Normalization in the Transformer Architecture” (Xiong et al., 2020)
- RoPE: “RoFormer: Enhanced Transformer with Rotary Position Embedding” (Su et al., 2021)
- FlashAttention: “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness” (Dao et al., 2022)
- GQA: “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints” (Ainslie et al., 2023)