
MLLM 기술 리뷰: Qwen3-VL, InternVL3.5, GLM-4.5V, Gemma 3
Published:
📌 Qwen3-VL
1. Introduction
Qwen3-VL은 Alibaba가 2025년 10월 공개한 Visual Agent와 Visual Coding 능력을 갖춘 차세대 멀티모달 모델이다. 또한 Advanced Spatial Perception을 통해 2D/3D grounding이 가능하며, Extended Context(256K → 1M tokens)로 긴 비디오와 문서를 처리할 수 있다.
기존 VLM들이 이미지 이해와 텍스트 생성에 집중했다면, Qwen3-VL은 실제 행동(action)을 수행하는 Visual Agent와 시각적 입력에서 코드를 생성하는 Visual Coding이라는 새로운 차원의 능력을 추가했다. 기존 VLM들은 주로 이미지-텍스트 정렬과 텍스트 생성에 집중했다. 하지만 실제 응용에서는 이미지를 보고 행동을 수행하거나, 스크린샷을 보고 코드를 생성하는 것처럼 더 복잡한 작업이 필요하다. 예를 들어, 사용자가 “이 앱의 로그인 버튼을 클릭해줘”라고 요청하면, 모델은 GUI 요소를 인식하고 실제 클릭 동작을 수행해야 한다. 또한 긴 비디오나 대규모 문서를 처리하려면 확장된 컨텍스트 윈도우가 필요하다. 기존 model들은 주로 4K~32K token 수준에서 작동했지만, Qwen3-VL은 256K를 기본으로 하고 1M까지 확장 가능하다. 이는 수시간 분량의 비디오나 전체 책을 한 번에 처리할 수 있게 해준다. 아 물론 실제로 얼마나 잘 되는지는 의문이긴 하다.
Qwen2.5-VL에서 Qwen3-VL로의 발전은 이렇듯 실용적인 방향으로 발전했다. 특히 Visual Agent와 Visual Coding은 실제 AI 어시스턴트나 개발 도구로 활용되기 위해 필수적인 능력이다.
2. Technical Approach
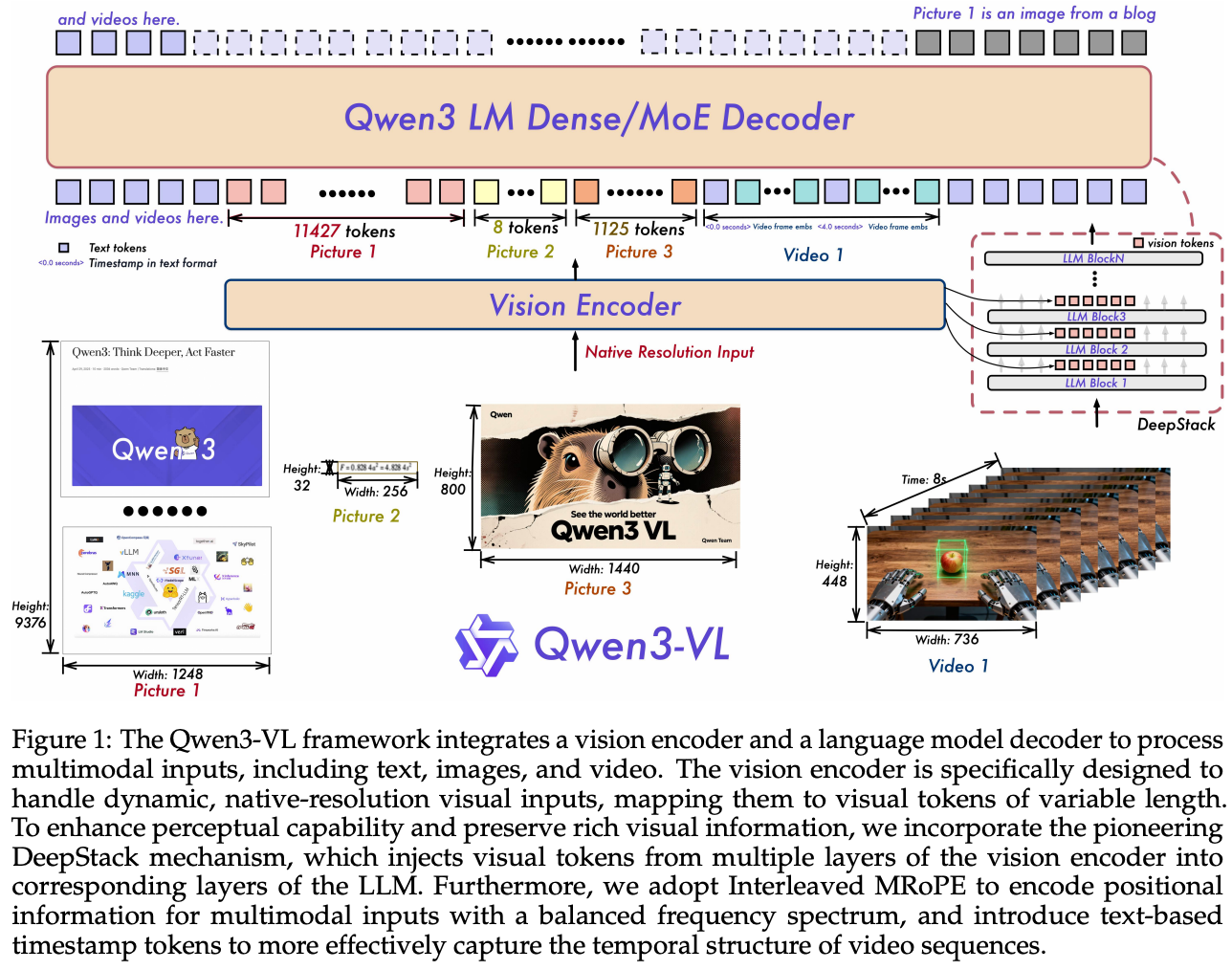
테크니컬 리포트에서 Qwen3-VL은 세 가지 핵심적인 개선을 설명한다.
2.1. Interleaved-MRoPE
Interleaved-MRoPE는 비디오와 같은 long context 추론을 위해 full-frequency positional embeddings를 도입했다. 기존 RoPE(Rotary Position Embedding)는 텍스트에 최적화되어 있어 비디오의 시간적 정보를 정확하게 인코딩하기 어려웠다.
기존 mRoPE의 한계
비디오를 처리하기 위한 기존 mRoPE(Multimodal RoPE) 방식(예: T-RoPE, Multi-Head RoPE)은 Time(T), Height(H), Width(W) 차원을 각각 분리하여 인코딩하는 방식이었다. 즉, 주파수 스펙트럼을 각 축별로 연속적인 블록으로 분할하여 T는 T만, H는 H만, W는 W만 담당하는 방식이었다.
예를 들어, hidden dimension이 128인 경우
- Channel 0~42: Time(T) 차원만 encoding
- Channel 43~85: Height(H) 차원만 encoding
- Channel 86~127: Width(W) 차원만 encoding
이 방식의 문제점은 각 attention head가 특정 차원에 집중하게 되어, 시간과 공간 정보가 분리되어 학습된다는 것이다. 이로 인해 시간-공간 간의 상호작용을 효과적으로 학습하기 어려웠다.
Interleaved-MRoPE의 개선
Interleaved-MRoPE는 T, H, W 차원을 분리하지 않고, channel별로 축 할당을 interleave시킨다. 즉, 각 channel이 T, H, W를 반복 순서로 할당받는다.
- Channel 0: Time(T)
- Channel 1: Height(H)
- Channel 2: Width(W)
- Channel 3: Time(T)
- Channel 4: Height(H)
- Channel 5: Width(W)
- …
이렇게 하면 모든 attention head가 시간과 공간 정보의 joint blend를 관찰하게 되어, spatio-temporal 상호작용을 효과적으로 학습할 수 있다. 또한 모든 축이 low, high frequency를 모두 활용할 수 있어 full-frequency utilization이 가능하다. 이는 사전 학습된 텍스트 prior를 보존하면서도 모든 frequency를 활용하고, 모달리티 간 위치 일관성을 유지한다.
세부사항
- Full-frequency 활용: 모든 주파수 대역을 모든 축(T, H, W)에서 활용하여 긴 시퀀스(256K token)에서도 정확한 위치 정보 유지
- Spatial encoding: 이미지 patch의 (x, y) 좌표를 rotary matrix 연산으로 encoding하여 공간적 인접 관계 보존
- Temporal encoding: 비디오 frame의 시간 축을 명시적으로 encoding하여 시간적 순서 이해 향상
- Interleaved 방식: T, H, W 차원을 channel별로 순환 할당하여 시간-공간 상호작용 학습 가능
2.2. DeepStack
DeepStack은 multi-level ViT features를 융합하여 fine-grained detail을 포착한다. 단일 레벨 특징만 사용하는 기존 방식과 달리, 여러 해상도의 시각 특징을 결합하여 텍스트 렌더링과 정밀 편집에 필요한 세부 정보를 보존한다.
핵심 아이디어
- Vision Transformer의 여러 레벨에서 추출된 특징을 융합
- 저resolution 특징: 전역적인 구조와 레이아웃 정보
- 고resolution 특징: 세부적인 텍스트, 경계, 스타일 정보
세부사항
- Multi-level feature extraction: ViT의 여러 layer에서 특징 추출
- Feature fusion: 여러 레벨의 특징을 효과적으로 결합하는 메커니즘
- Fine-grained detail preservation: 작은 텍스트나 세밀한 디테일 보존
- Resolution별 특징 활용: 각 resolution에서 중요한 정보 추출
DeepStack은 Visual Coding에서 정확한 레이아웃과 스타일 정보를 보존하여, 이미지나 비디오에서 코드를 생성할 때 원본의 구조와 디자인을 정확히 반영할 수 있게 해준다. OCR 작업에서는 작은 텍스트 인식 정확도가 향상되어, 문서나 스크린샷에서 미세한 글자까지 정확히 읽을 수 있다. 또한 이미지 편집 작업에서 세부 정보 손실을 최소화하여, 고해상도 이미지의 디테일을 유지하면서 편집할 수 있다.
2.3. Text-Timestamp Alignment
Text-Timestamp Alignment는 비디오의 temporal modeling을 위해 정확한 timestamp-grounded event localization을 수행한다. 텍스트와 비디오 frame 간의 시간적 대응 관계를 학습하여 긴 비디오에서도 정확한 이벤트 추적이 가능하다.
핵심 아이디어
- 텍스트 설명과 비디오 frame 간의 명시적 시간적 대응 관계 학습
- 이전의 T-RoPE 방식에서 명시적 text-timestamp 정렬로 진화
- 긴 비디오에서도 특정 이벤트를 정확히 추적 가능
세부사항
- Timestamp grounding: 텍스트의 각 단어/구를 특정 비디오 frame에 매핑
- Event localization: 비디오에서 특정 이벤트가 발생하는 정확한 시간 추적
- Temporal alignment: 텍스트와 비디오의 시간적 순서 일치 보장
- Long video handling: 긴 비디오에서도 시간적 정보 유지
Text-Timestamp Alignment는 긴 비디오에서 특정 이벤트나 장면을 정확히 찾을 수 있게 해준다. 비디오 질문 응답에서는 정확한 시간적 맥락을 이해하여 “5분 30초 시점에서 무슨 일이 일어났나요?”와 같은 질문에 정확하게 답할 수 있다. 또한 비디오 요약에서 중요한 이벤트 추출 정확도가 향상되어, 긴 비디오의 핵심 장면을 효과적으로 요약할 수 있다.
3. Experimental Results
Qwen3-VL은 다양한 벤치마크에서 우수한 성능을 보였다. Visual Agent 작업에서는 PC/mobile GUI 조작 벤치마크에서 최고 성능을 달성했으며, 모델이 스크린샷을 보고 GUI 요소를 정확히 인식하고 클릭, 스크롤, 입력 등의 동작을 수행할 수 있음을 입증했다. Visual Coding에서는 이미지나 비디오에서 Draw.io 다이어그램, HTML/CSS/JS 코드를 생성하는 작업에서 높은 정확도를 보였다. 특히 레이아웃과 스타일 정보를 정확하게 보존하여 실행 가능한 코드를 생성할 수 있었다.
Spatial reasoning 작업에서는 객체 위치 판단, 시점 추정, occlusion 분석에서 강력한 성능을 보였으며, 2D/3D grounding 작업에서도 정확한 공간 인식을 달성했다. 이는 로봇 공학이나 AR/VR 응용에서 중요한 능력이다. OCR 성능은 32개 언어에서 저조도나 블러 조건에서도 강건하게 작동했으며, 특히 중국어와 같은 복잡한 문자 시스템에서도 높은 정확도를 보였다.
Extended Context 능력은 긴 비디오 이해와 대규모 문서 처리에서 실질적인 이점을 보여줬다. 256K token context로 수시간 분량의 비디오를 한 번에 처리할 수 있었으며, 비디오 전체의 맥락을 유지하면서 특정 이벤트나 장면에 대한 질문에 정확하게 답할 수 있었다. 1M token 확장 시 전체 책을 맥락으로 유지하면서 질문에 답할 수 있었으며, 문서 간 참조와 교차 참조도 정확하게 수행했다.
4. Conclusion
Qwen3-VL의 기술적 특이점은 세 가지 핵심 아키텍처 개선에 있다. Interleaved-MRoPE는 기존 mRoPE의 T-H-W 분리 인코딩 방식을 채널별 순환 할당으로 전환하여 시간-공간 상호작용을 효과적으로 학습할 수 있게 했다. DeepStack은 multi-level ViT features를 융합하여 fine-grained detail을 보존하며, 특히 Visual Coding과 OCR 작업에서 정확한 레이아웃과 작은 텍스트 인식이 가능하다. Text-Timestamp Alignment는 명시적 timestamp grounding을 통해 긴 비디오에서도 정확한 이벤트 추적이 가능하다.
Extended Context(256K → 1M token)와 Advanced Spatial Perception은 이러한 기술적 기반 위에서 실현되었다. 특히 Interleaved-MRoPE의 full-frequency utilization은 긴 시퀀스에서도 정확한 위치 정보를 유지하는 핵심 메커니즘이다.
📌 InternVL3.5
1. Introduction
InternVL3.5는 OpenGVLab이 2025년 8월 공개한 효율성과 성능을 동시에 개선한 오픈소스 멀티모달 모델로, Qwen 시리즈 다음으로 자주 등장하는 모델이 아닐까 싶다.
기존 멀티모달 모델들은 성능 향상에 집중했지만, 추론 속도와 메모리 효율성은 상대적으로 소홀했다. InternVL3.5는 성능과 효율성을 동시에 개선하는 것이 실용적 배포에 필수적임을 보여준다. 특히 추론 속도 약 4배 향상은 실시간 응용에서 큰 차이를 만든다.
기존 InternVL3는 다양한 멀티모달 작업에서 좋은 성능을 보였지만, 추론 속도와 메모리 효율성 측면에서 개선이 필요했다. 특히 대규모 모델을 배포할 때는 단일 GPU의 메모리 제약이 큰 문제였다. 또한 모든 이미지를 동일한 해상도로 처리하는 것은 비효율적이다. 문서의 배경 부분은 낮은 해상도로 충분하지만, 텍스트가 있는 부분은 높은 해상도가 필요하다. 기존 방식은 모든 이미지를 동일한 해상도로 처리하여 불필요한 계산을 수행했다.
효율성과 성능의 트레이드오프는 멀티모달 모델의 핵심 과제다. GUI interaction이나 embodied agency 같은 실시간 응용에서는 추론 속도가 사용자 경험을 결정한다. 사용자가 GUI 요소를 클릭하라고 요청했을 때, 모델이 몇 초씩 걸려서 응답한다면 실용적이지 않다. InternVL3.5는 이 문제를 세 가지 기술로 해결했다.
2. Technical Approach
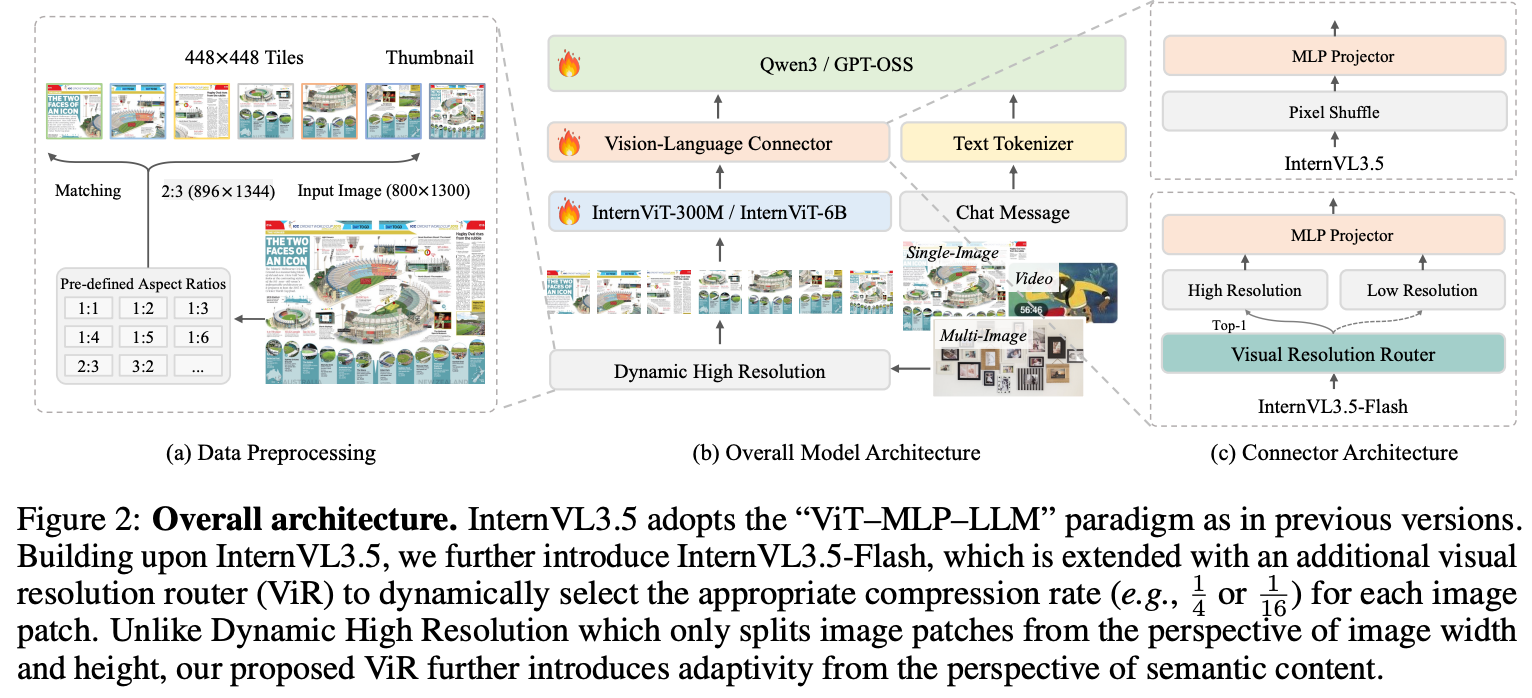
InternVL3.5는 효율성과 성능을 동시에 개선하기 위해 세 가지 핵심 기술을 제안했다.
2.1. Cascade Reinforcement Learning
Cascade RL은 두 단계 학습 프레임워크로, 먼저 Offline RL로 안정적인 수렴을 달성한 후 Online RL로 정밀한 정렬을 수행한다. 이 coarse-to-fine 전략은 추론 성능을 크게 향상시키면서도 학습 안정성을 유지한다.
Stage 1: Offline RL (Mixed Preference Optimization)
- 목적: 안정적인 수렴 달성
- 방법: Mixed Preference Optimization (MPO) 사용
- Loss Fuction:
- Preference loss: 인간 선호도 데이터로부터 학습
- Quality loss: 응답 품질 평가
- Generation loss: 생성 능력 향상
- 효과: 초기 단계에서 안정적인 정책 학습
Stage 2: Online RL (Group Sequence Policy Optimization)
- 목적: 정밀한 정렬 수행
- 방법: GSPO (Group Sequence Policy Optimization) 알고리즘
- 핵심 메커니즘:
- 여러 후보 응답 생성
- 각 후보의 정규화된 advantage 계산
- Advantage 기반 정책 정제
- 효과: 모델이 생성한 응답을 직접 활용하여 정책 개선
세부사항
- Coarse-to-fine 전략: coarse 정렬 → 정밀한 정렬
- 학습 안정성: Offline RL로 초기 안정성 확보 후 Online RL 적용
- Advantage 정규화: 여러 후보 간 비교를 통한 안정적 학습
- 성능 향상: MMMU, MathVista 같은 추론 작업에서 최대 +16.0% 성능 향상
2.2. Visual Resolution Router (ViR)
Visual Resolution Router (ViR)는 성능 저하 없이 동적으로 시각 토큰 해상도를 조정한다. 각 이미지 패치를 평가하여 압축률을 결정하며, 입력 이미지의 복잡도에 따라 적절한 해상도를 선택한다.
핵심 아이디어
- 이미지의 모든 영역이 동일한 해상도를 필요로 하지 않음
- semantic하게 중요한 영역(텍스트, 객체)은 높은 해상도 유지
- 덜 중요한 영역(배경)은 낮은 해상도로 압축
세부사항
- Patch 평가: 각 이미지 patch의 중요도 평가
- 동적 압축: 중요도에 따라 압축률 결정
- 덜 중요한 patch는 최대 64 token까지 압축
- 중요한 patch는 최대 256 token까지 보존
- 성능 보존: 압축 과정에서 중요한 정보 손실 최소화
ViR는 문서 및 OCR 작업에서 token 수를 약 50% 감소시키면서도 측정 가능한 성능 저하 없이 처리할 수 있게 해준다. 이는 계산 비용을 대폭 감소시킨다. 특히 문서 처리에서 효과적이며, 텍스트 영역은 고해상도로 보존하고 배경은 저해상도로 압축하여 효율성과 성능을 동시에 확보한다.
2.3. Decoupled Vision-Language Deployment (DvD)
Decoupled Vision-Language Deployment (DvD)는 Vision encoder와 LLM을 서로 다른 GPU에 분리 배치하여 계산 부하를 균형있게 분산시킨다. 이는 메모리 제약이 있는 환경에서도 대규모 모델을 효율적으로 배포할 수 있게 해준다.
핵심 아이디어
- Vision encoder와 LLM의 계산 부하가 다름
- 단일 GPU에 모두 배치하면 메모리 부족 또는 비효율적 리소스 사용
- 서로 다른 GPU에 분리 배치하여 부하 균형
세부사항
- Vision Encoder 배치: 별도 GPU에 배치
- 이미지 인코딩 작업 수행
- 시각 토큰 생성
- LLM 배치: 다른 GPU에 배치
- 시각 token과 텍스트를 함께 처리
- 최종 응답 생성
- 통신 최적화: GPU 간 데이터 전송 최소화
DvD는 추론 속도를 최대 4배 향상시키고 throughput을 2배 증가시킨다. 메모리 제약 환경에서도 대규모 모델을 배포할 수 있게 해주며, Vision encoder와 LLM의 계산 부하를 균형있게 분산시켜 리소스 활용 효율성을 향상시킨다.
3. Experimental Results
InternVL3.5는 추론 성능과 효율성 모두에서 큰 향상을 보였다. Cascade RL을 통해 MMMU, MathVista 같은 추론 벤치마크에서 InternVL3 대비 최대 +16.0% 성능 향상을 달성했다. 이는 두 단계 학습 전략이 추론 능력을 크게 향상시킴을 보여준다.
ViR를 통해 token 수를 약 50% 감소시키면서도 성능 저하 없이 처리할 수 있었으며, 이는 문서나 OCR 작업에서 특히 효과적이었다. 덜 중요한 이미지 영역은 낮은 resolution으로 처리하고, 텍스트나 중요한 객체가 있는 영역은 높은 resolution으로 보존하여 효율성과 성능을 동시에 확보했다.
DvD를 통해 추론 속도가 4배 향상되었으며, throughput도 2배 증가했다. 이는 Vision encoder와 LLM을 다른 GPU에 분리 배치함으로써 계산 부하를 균형있게 분산시킨 결과다. 특히 메모리 제약이 있는 환경에서도 대규모 모델을 효율적으로 배포할 수 있게 해주었다.
GUI interaction 작업에서도 우수한 성능을 보였으며, open-source MLLM 중에서 SOTA 성능을 달성했다. 특히 InternVL3.5-241B-A28B는 일반 멀티모달, 추론, 텍스트, 에이전트 작업에서 오픈소스 MLLM 중 최고 성능을 보이며, GPT-5 같은 상용 모델과의 격차를 좁혔다.
4. Conclusion
InternVL3.5의 기술적 특이점은 효율성과 성능을 동시에 개선한 세 가지 핵심 기술에 있다. Cascade RL은 Offline RL과 Online RL의 두 단계 학습으로 안정적 수렴과 정밀한 정렬을 동시에 달성하며, MMMU, MathVista 같은 추론 작업에서 최대 +16.0% 성능 향상을 보였다. ViR는 이미지 patch별로 중요도를 평가하여 동적으로 token 수를 조정하며, 문서 및 OCR 작업에서 token 수를 약 50% 감소시키면서도 성능 저하 없이 처리한다. DvD는 Vision encoder와 LLM을 서로 다른 GPU에 분리 배치하여 추론 속도를 최대 4.05배 향상시키고 throughput을 2배 증가시켰다.
특히 DvD는 단일 GPU의 메모리 제약을 극복하는 새로운 배포 전략이며, ViR는 모든 이미지를 동일한 resolution으로 처리하는 기존 방식의 비효율성을 해결하는 동적 해상도 조정 메커니즘이다.
📌 GLM-4.5V
1. Introduction
GLM-4.5V는 Zhipu AI와 Tsinghua University가 2025년 7월 1일 테크리포트에서 소개된 RLCS(Reinforcement Learning with Curriculum Sampling)를 포함한 스케일러블 멀티모달 RL 레시피를 기반으로, 2025년 8월 11일경 공개/배포된 VLM이다. GLM-4.5V는 GLM-4.5-Air 기반(MoE, 106B total / 12B active)이며, RLCS를 포함한 멀티모달 RL 스택(RLVR + RLHF, unified reward system, dynamic sampling expansion 등)을 통해 멀티모달 추론 능력을 강화한 모델이다.
기존 멀티모달 모델들은 다양한 도메인에서 학습하지만, 모델이 현재 잘할 수 있는 작업과 어려운 작업을 구분하지 않고 동일하게 학습한다. RLCS는 모델의 역량에 따라 학습할 태스크를 동적으로 선택하여 효율적이고 안정적인 학습을 가능하게 한다. 이는 curriculum learning의 아이디어를 reinforcement learning에 적용한 것이다.
기존 GLM-V 시리즈는 멀티모달 이해 능력을 꾸준히 발전시켜왔다. 하지만 복잡한 추론 작업, 특히 STEM 문제나 코딩 작업에서는 여전히 개선의 여지가 있었다. Multimodal reasoning은 단순히 이미지를 보고 텍스트를 생성하는 것을 넘어, 이미지의 내용을 분석하고 논리적으로 추론하는 능력이 필요하다. 예를 들어, 수학 문제의 그래프를 보고 문제를 해결하거나, 코드 스크린샷을 보고 버그를 찾는 것은 단순한 이미지 설명과는 다른 추론 능력이 필요하다.
Reinforcement Learning은 LLM에서 추론 능력을 향상시키는 데 효과적이지만, 멀티모달 모델에 적용할 때는 여러 도메인(STEM, 코딩, GUI agent 등)에서의 성능을 균형있게 향상시키는 것이 어렵다. 모델이 한 도메인에서는 잘 학습하지만 다른 도메인에서는 성능이 떨어지는 불균형 문제가 발생할 수 있다. RLCS는 이 문제를 curriculum sampling으로 해결한다. 모델의 현재 역량을 평가하고, 그에 맞는 난이도의 태스크를 선택하여 점진적으로 어려운 작업으로 확장하는 방식이다.
2. Technical Approach

GLM-4.5V의 핵심은 Reinforcement Learning with Curriculum Sampling (RLCS)를 포함한 멀티모달 RL 스택이다. RLCS는 multi-domain reinforcement learning을 통해 모델의 역량에 따라 동적으로 태스크를 선택하는 방식이며, RLVR + RLHF, unified reward system, dynamic sampling expansion 등과 함께 멀티모달 RL 레시피의 한 구성요소로 작동한다.
2.1. RLCS 프레임워크 개요
RLCS는 curriculum learning의 아이디어를 reinforcement learning에 적용한 프레임워크다. Curriculum learning은 인간이 학습할 때 쉬운 내용부터 시작하여 점진적으로 어려운 내용으로 확장하는 것처럼, model도 쉬운 task부터 시작하여 점진적으로 어려운 task로 확장하는 학습 전략이다. 기존 RL 방식은 모든 도메인과 난이도를 동일하게 학습하지만, RLCS는 model이 현재 잘 수행할 수 있는 task부터 시작하여 점진적으로 어려운 task로 확장한다.
핵심 아이디어
- Curriculum learning의 아이디어를 reinforcement learning에 적용
- Model이 현재 잘 수행할 수 있는 task부터 시작하여 점진적으로 어려운 task로 확장
- Model의 역량에 따라 동적으로 학습할 task 선택
학습은 여러 단계로 진행된다. 첫째, 다양한 지식 집약적 멀티모달 데이터로 vision foundation model을 대규모 pre-training을 진행한다. 둘째, long-context, 고해상도, 비디오 처리를 위한 continual training을 수행한다. 셋째, SFT(Supervised Fine-Tuning) 단계에서 long CoT(Chain-of-Thought) 스타일 정렬을 수행한다. 마지막으로 RLCS를 포함한 멀티모달 RL 스택(RLVR + RLHF, unified reward system, dynamic sampling expansion 등)을 적용한다. 이 단계에서 model의 역량을 평가하고 그에 맞는 난이도의 task를 선택하여 점진적으로 어려운 작업으로 확장한다.
학습 단계
- Pre-training: 다양한 지식 집약적 멀티모달 데이터로 vision foundation model 사전 학습
- Continual Training: long-context, 고해상도, 비디오 처리를 위한 지속적 학습
- SFT: 롱 CoT 스타일 정렬을 위한 Supervised Fine-Tuning
- Multi-modal RL: RLCS를 포함한 RL 스택(RLVR + RLHF, unified reward system, dynamic sampling expansion 등) 적용
2.2. 동적 태스크 선택 메커니즘
RLCS의 핵심은 model이 각 도메인(STEM, 코딩, GUI agent 등)에서의 성능을 지속적으로 평가하고, 그 결과를 바탕으로 학습 전략을 조정하는 것이다.
도메인별 성능 평가
- Model이 각 도메인(STEM, 코딩, GUI agent 등)에서의 성능을 지속적으로 평가
- 성능 평가 결과를 바탕으로 학습 전략 조정
Model이 수학 문제는 잘 풀지만 코딩 문제는 어려워한다면, 코딩 task의 난이도를 낮추고 더 많은 코딩 샘플을 제공한 후, 점진적으로 코딩 task의 난이도를 증가시킨다. 반대로 성능이 좋은 도메인에서는 더 어려운 task로 확장하여 model의 능력을 더욱 향상시킨다.
태스크 선택 전략
- 성능이 좋은 도메인: 더 어려운 task로 확장
- 성능이 낮은 도메인: 난이도를 낮추거나 더 많은 샘플 제공
- 예시: Model이 수학 문제는 잘 풀지만 코딩 문제는 어려워한다면
- 코딩 task의 난이도를 낮춤
- 더 많은 코딩 샘플 제공
- 점진적으로 코딩 task의 난이도 증가
이러한 동적 태스크 선택은 multi-domain RL을 통해 여러 도메인에서 동시에 학습하면서도, 각 도메인의 성능에 따라 난이도를 조정한다. 이를 통해 도메인 간 성능 불균형을 방지하고, 점진적 난이도 증가로 학습 안정성을 확보한다.
세부사항
- Multi-domain RL: 여러 도메인에서 동시에 학습
- 동적 난이도 조정: Model의 현재 역량에 따라 task 난이도 조정
- 균형 학습: 도메인 간 성능 불균형 방지
- 안정적 학습: 점진적 난이도 증가로 학습 안정성 확보
2.3. 학습 효율성과 성능 향상
RLCS는 model이 이미 잘하는 작업에 시간을 낭비하지 않고, 어려운 작업에 집중하여 효율적으로 학습할 수 있게 해준다. 멀티모달 RL 단계(RLCS를 포함한 여러 안정화/샘플링 레시피 포함)가 최대 +10.6% 성능 향상을 보였으며, 다양한 도메인(STEM, 코딩, GUI agent, 비디오 이해)에서 균형있게 성능을 향상시켰다. 특히 작은 model(GLM-4.1V-9B-Thinking)에서도 효과적으로 작동하여, curriculum sampling이 model의 잠재력을 효율적으로 발휘하게 해준다는 것을 보여준다.
3. Experimental Results
GLM-4.5V는 42개 공개 benchmark에서 오픈소스 model 중 SOTA 성능을 달성했다. STEM 문제 해결에서는 수학, 물리, 화학 문제에서 강력한 성능을 보였으며, 특히 그래프나 다이어그램을 포함한 복잡한 문제에서도 정확한 추론을 수행할 수 있었다. 코딩 작업에서는 이미지나 비디오에서 코드를 생성하거나 코드를 분석하는 작업에서 우수한 결과를 보였으며, 스크린샷을 보고 실행 가능한 코드를 생성할 수 있었다.
GUI agent 작업에서는 스크린샷을 보고 GUI 요소를 인식하고 작업을 수행하는 능력에서 closed-source 모델인 Gemini-2.5-Flash와 경쟁력 있는 성능을 보였다. 이는 RLCS를 포함한 멀티모달 RL 스택이 다양한 도메인에서 균형있게 성능을 향상시켰음을 보여준다.
특히 GLM-4.1V-9B-Thinking은 단 9B parameter로도 72B parameter의 Qwen2.5-VL-72B보다 29개 benchmark에서 우수한 성능을 보여, 효율성과 성능의 균형을 잘 달성했다. 이는 RLCS를 포함한 멀티모달 RL 스택이 작은 모델에서도 효과적으로 작동함을 보여주며, curriculum sampling이 모델의 잠재력을 효율적으로 발휘하게 해준다는 것을 입증한다.
4. Conclusion
GLM-4.5V의 기술적 특이점은 RLCS (Reinforcement Learning with Curriculum Sampling)를 포함한 멀티모달 RL 스택이다. RLCS는 curriculum learning의 아이디어를 reinforcement learning에 적용하여, model의 역량에 따라 동적으로 학습할 task를 선택하는 방식이다. 기존 RL 방식이 모든 도메인을 동일하게 학습하여 불균형 문제가 발생했던 것과 달리, RLCS는 도메인별 성능을 지속적으로 평가하고 그에 맞는 난이도의 task를 선택하여 점진적으로 어려운 작업으로 확장한다. RLCS는 RLVR + RLHF, unified reward system, dynamic sampling expansion 등과 함께 멀티모달 RL 레시피의 한 구성요소로 작동한다.
이를 통해 멀티모달 RL 단계(여러 안정화/샘플링 레시피 포함)가 최대 +10.6% 성능 향상을 달성했으며, 특히 작은 model(GLM-4.1V-9B-Thinking)도 큰 model(Qwen2.5-VL-72B) 대비 우수한 성능을 보여, curriculum sampling이 model의 잠재력을 효율적으로 발휘하게 해준다는 것을 입증했다.
📌 Gemma 3
1. Introduction
Gemma 3는 Google DeepMind가 2025년 3월 공개한 경량 오픈 모델 시리즈에 멀티모달 비전 능력을 추가한 모델이다. Pan and Scan (P&S) 방법으로 유연한 이미지 해상도를 지원하며, Local/Global Attention 혼합 구조로 128K 토큰 컨텍스트를 효율적으로 처리한다.
Google Gemma 시리즈는 오픈소스 경량 LLM으로 출발했다. Gemma 2까지는 텍스트 전용 모델이었지만, 실제 응용에서는 이미지와 텍스트를 함께 처리하는 능력이 필요하기에 MLLM으로 발전했다.
경량 model에 멀티모달 능력을 추가할 때의 주요 과제는 메모리 효율성이다. Vision encoder는 많은 token을 생성하며, 긴 context를 처리하려면 KV-cache 메모리가 급격히 증가한다. 예를 들어, 128K token context를 처리하려면 KV-cache만으로도 수 GB의 메모리가 필요하다. Gemma 3는 이 문제를 Local/Global Attention 혼합 구조로 해결했다.
2. Technical Approach
Gemma 3는 경량 model에 멀티모달 능력을 효율적으로 추가하기 위해 몇 가지 핵심 설계를 채택했다.
2.1. SigLIP Vision Encoder
SigLIP Vision Encoder는 이미지를 256개의 고정된 soft token으로 encoding한다. 이는 메모리 효율성을 보장하면서도 충분한 시각 정보를 전달하는 핵심 설계다.
핵심 아이디어
- 고정된 token 수(256개)로 메모리 사용 예측 가능
- Contrastive learning으로 학습된 vision encoder
- 이미지-텍스트 정렬에 효과적
세부사항
- 이미지 정규화: 896x896 resolution으로 정규화
- Token 수 제한: 256개의 고정된 soft token
- 메모리 효율성: 제한된 token 수로 메모리 사용 최소화
- 정보 보존: 충분한 시각 정보 전달
SigLIP Vision Encoder는 고정된 token 수로 메모리 사용량을 예측 가능하게 하여 경량 model에 적합한 설계다. 256개의 soft token으로 제한하면서도 이미지-텍스트 정렬 성능이 우수하여, 메모리 효율성과 성능의 균형을 잘 달성한다.
2.2. Pan and Scan (P&S)
Pan and Scan (P&S) 방법은 LLaVA에서 영감을 받아 유연한 이미지 resolution을 지원한다. 고정된 resolution 대신 다양한 종횡비의 이미지를 효율적으로 처리할 수 있게 해준다.
Pan and Scan은 고해상도나 비정사각형 이미지를 고정된 resolution으로 리사이즈하는 대신, adaptive windowing 알고리즘을 통해 이미지를 여러 개의 겹치지 않는 crop으로 분할한다. 각 crop은 원본 이미지의 aspect ratio를 유지한 채로 독립적으로 vision encoder에 의해 처리되며, 이후 language model에서 통합된다. 이 방식은 이미지를 강제로 정사각형으로 변형하거나 해상도를 낮추지 않아도 되므로, 왜곡 없이 다양한 종횡비의 이미지를 효율적으로 처리할 수 있다. 예를 들어, 가로로 긴 파노라마 이미지나 세로로 긴 포스터 이미지도 원본 비율을 유지하면서 여러 개의 crop으로 나누어 처리할 수 있다.
핵심 아이디어
- 실제 응용에서는 다양한 크기와 비율의 이미지가 입력됨
- 고정된 resolution은 이미지 왜곡이나 정보 손실 발생 가능
- 유연한 resolution 처리로 다양한 이미지 효율적 처리
세부사항
- 종횡비 유지: 원본 이미지의 종횡비 보존
- 효율적 처리: 다양한 크기의 이미지를 효율적으로 처리
- 정보 손실 최소화: 이미지 왜곡 최소화
2.3. Local/Global Attention
Local/Global Attention 혼합 구조는 긴 컨텍스트를 처리하면서도 KV-cache 메모리 증가를 관리하기 위한 핵심 설계다. 이는 경량 모델에서 긴 컨텍스트를 지원하는 혁신적인 방법이다.
핵심 아이디어
- 긴 컨텍스트를 처리하려면 KV-cache 메모리가 급격히 증가
- 모든 토큰에 대해 global attention을 수행하면 메모리 부족
- Local attention과 Global attention을 혼합하여 효율성과 성능 균형
세부사항
- Local Attention Layer:
- 1024 token 범위에서 작동
- 근처 token만 참조하여 메모리 사용 제한적
- 빠른 계산 가능
- Global Attention Layer:
- 전체 시퀀스에 attention 수행
- 전체 맥락 유지
- 5개의 local layer마다 1개의 global layer 배치 (5:1 비율)
- 혼합 구조:
- Local layer: 빠른 처리, 제한된 메모리
- Global layer: 전체 맥락 유지
- 두 가지를 적절히 혼합하여 효율성과 성능 확보
Local/Global Attention 혼합 구조는 128K token context를 지원하면서도 KV-cache 메모리 증가를 크게 제한한다. 모든 layer에서 full attention을 수행하는 경우와 비교하면, local layer는 1024 token window만 사용하므로 KV cache 메모리 사용량이 크게 감소한다. Global layer는 전체 128K token에 attention하지만 전체 layer의 약 1/6(5:1 비율)만 global layer이므로, 전체적인 메모리 사용량은 full attention 대비 현저히 낮다.
2.4. RoPE Rescaling for Long Context
RoPE Rescaling은 128K token의 long context를 지원하기 위한 기술이다. 모델은 처음부터 128K sequence로 학습하는 대신, 32K sequence로 pre-training 후 RoPE rescaling을 통해 4B, 12B, 27B model을 128K token으로 확장한다.
RoPE는 각 위치에 rotation angle을 할당하여 위치 정보를 인코딩한다. 표준 RoPE는 학습 시 본 적 없는 긴 위치에 대해 extrapolation을 시도하지만, 먼 거리의 단어들이 매우 유사한 embedding 값을 가지게 되어 상대적 위치를 구분하기 어려워진다.
“Extending Context Window of Large Language Models via Positional Interpolation” (Chen et al., 2023)에서 제안한 Position Interpolation은 이를 interpolation 문제로 재구성한다. 위치 인덱스를 스케일링하여 모델이 학습한 원래 범위 내에 유지하는 방식이다. 예를 들어, 2,048 token으로 학습된 모델이 4,096 token을 처리해야 할 때, 위치 4,096을 위치 2,048로 매핑하여 rotation angle이 모델이 익숙한 범위 내에 있도록 한다. Scaling factor는 s = new_context_length / old_context_length로 계산되며, 이는 RoPE의 rotation angle 계산에 적용된다.
핵심 아이디어
- 32K sequence로 pre-training 후 RoPE rescaling으로 128K로 확장
- positional interpolation과 유사한 과정 사용
- Scaling factor 8이 실용적으로 잘 작동함 (128K / 32K = 4이지만, 실제로는 8 사용)
세부사항
- RoPE Base Frequency 조정: Global self-attention layer의 RoPE base frequency를 Gemma 2의 10k에서 1M으로 증가시킴. 이는 긴 컨텍스트에서 더 정밀한 위치 인코딩을 가능하게 한다.
- Local Layer Frequency 유지: Local self-attention layer는 10k frequency 유지
- Positional Interpolation: Global self-attention layer의 span을 확장하기 위해 positional interpolation 과정 적용. 위치 인덱스를 스케일링하여 학습 범위 내에 유지
- Scaling Factor: 실험적으로 scaling factor 8이 효과적임을 확인
2.5. Knowledge Distillation
Gemma 3는 사전 학습 단계에서 Knowledge Distillation을 적용하여 경량 model의 성능을 향상시켰다. 이를 통해 Gemma3-4B-IT가 Gemma2-27B-IT와 경쟁력 있는 성능을 달성할 수 있었으며, 작은 model이 큰 model의 성능에 근접할 수 있게 해주어 경량 model의 실용성을 크게 향상시켰다. 또한 novel post-training recipe와 결합하여 수학, 추론, 채팅, 지시 수행, 다국어 능력을 크게 향상시켜 경량 model도 충분히 강력한 성능을 달성할 수 있게 했다.
3. Experimental Results
Gemma 3는 경량 모델임에도 불구하고 강력한 성능을 보였다. Gemma3-4B-IT는 Gemma2-27B-IT와 경쟁력 있는 성능을 달성했으며, 이는 Knowledge Distillation과 효율적인 아키텍처 설계의 효과를 보여준다. 작은 model이 큰 model의 성능에 근접할 수 있다는 것은 경량 model의 실용성을 크게 향상시킨다.
Gemma3-27B-IT는 Gemini-1.5-Pro와 비교 가능한 성능을 보였으며, 특히 수학, 추론, 채팅, 지시 수행 능력에서 크게 향상되었다. 이는 novel post-training recipe의 효과를 보여주며, 경량 모델도 충분히 강력한 성능을 달성할 수 있음을 입증한다.
Extended Context 능력은 긴 문서 처리와 멀티턴 대화에서 실질적인 이점을 제공했다. 128K token context로 긴 문서를 한 번에 처리할 수 있었으며, 문서 전체의 맥락을 유지하면서 특정 부분에 대한 질문에 정확하게 답할 수 있었다. 또한 멀티턴 대화에서도 대화 맥락을 오래 유지할 수 있어, 사용자와의 긴 대화에서도 일관성 있는 응답을 제공할 수 있었다.
Local/Global Attention 혼합 구조는 메모리 효율성을 크게 향상시켰다. 긴 컨텍스트를 처리하면서도 KV-cache 메모리 증가를 제한하여, 소비자용 하드웨어에서도 실행 가능하게 했다.
4. Conclusion
Gemma 3의 기술적 특이점은 경량 model에 멀티모달 능력을 효율적으로 추가한 설계에 있다. Local/Global Attention 혼합 구조는 5:1 비율로 local layer(1024 token span)와 global layer를 배치하여, 128K token context를 지원하면서도 KV-cache 메모리 증가를 제한한다. 이는 모든 token에 대해 global attention을 수행하는 기존 방식의 메모리 문제를 해결하는 핵심 메커니즘이다. SigLIP Vision Encoder는 이미지를 256개의 고정된 soft token으로 encoding하여 메모리 사용량을 예측 가능하게 하며, Pan and Scan 방법으로 다양한 종횡비의 이미지를 효율적으로 처리한다. Knowledge Distillation은 사전 학습 단계에서 사용되어 Gemma3-4B-IT가 Gemma2-27B-IT와 경쟁력 있는 성능을 달성할 수 있게 했다.
이러한 기술적 설계를 통해 경량 model(1B ~ 27B parameter)이 소비자용 하드웨어에서도 실행 가능하면서도 강력한 멀티모달 성능을 제공한다.
아 앞선 3개의 중국 모델과 달리 유일하게 미국 모델이라는 점도 특이점이라 볼 수 있다.
💡 Discussion
MLLM 기술 트렌드
2024-2025년에 등장한 최신 VLM들은 기존 모델들이 해결하지 못했던 실용적 문제들에 집중했다. 네 모델 모두 공통적으로 실용성과 효율성을 강조하며, 단순한 벤치마크 성능 향상을 넘어 실제 응용에 필요한 능력을 갖추고 있다. 각 모델은 서로 다른 접근법과 강점을 가지고 있으며, 서로 다른 문제를 해결하려고 한다.
Visual Agent와 GUI 상호작용 능력이 Qwen3-VL과 InternVL3.5에서 두드러진다. Qwen3-VL은 Visual Agent/Coding 능력을 향상시켰고, InternVL3.5는 효율적인 GUI 처리로 실용적 배포를 강조한다. 효율성 개선 측면에서는 InternVL3.5의 DvD가 4배 속도 향상과 메모리 효율성을 달성했으며, Gemma 3의 Local/Global Attention은 경량 설계로 long context(128K token)를 지원한다.
확장된 Context Window는 Qwen3-VL(1M token)과 Gemma 3(128K token)에서 두드러진다. Qwen3-VL은 1M token으로 수시간 분량의 비디오나 전체 책을 처리할 수 있으며, Gemma 3는 128K token으로 긴 문서를 효율적으로 처리한다. 공간 인식 및 3D grounding 능력은 Qwen3-VL의 Advanced Spatial Perception에서 두드러지며, 객체 위치, 시점, 가림 판단을 통해 로봇 공학이나 AR/VR 응용을 지원한다.
Reinforcement Learning을 통한 성능 향상은 GLM-4.5V와 InternVL3.5에서 공통적으로 사용된다. GLM-4.5V의 RLCS는 curriculum sampling을 RL에 적용하여 멀티도메인 추론 능력을 강화했으며, InternVL3.5의 Cascade RL은 안정적 수렴과 정밀한 정렬을 동시에 달성했다. 적용 시나리오별로는 Visual Agent나 GUI 조작이 필요한 경우 Qwen3-VL 또는 InternVL3.5가 적합하고, 긴 컨텍스트 처리에는 Qwen3-VL 또는 Gemma 3를, 효율적 배포에는 InternVL3.5 또는 Gemma 3를, 복잡한 추론 작업에는 GLM-4.5V 또는 InternVL3.5를, 경량/엣지 디바이스에는 Gemma 3가 적합하다.
전반적으로 이번 세대의 VLM들은 상세한 이미지 이해와 분석 능력 향상, 비디오와 다양한 비율의 이미지를 분석하기 위한 개선, 그리고 효율성 개선이 주요 트렌드로 이루어졌다.
향후 전망
VLM 기술은 실용성과 효율성을 중심으로 발전하고 있다. 단순한 벤치마크 성능 향상을 넘어 실제 응용에 필요한 능력(Visual Agent, 효율성, long context)을 갖추는 것이 중요해지고 있다. 오픈소스 vs Closed-source 경쟁 또한 계속되고 있다. 오늘 살펴본 네 모델은 모두 오픈소스로 공개되었으며, 상용 모델(GPT-5, Gemini 등)과 경쟁력 있는 성능을 보이고 있다.
모델 성능 측면에서는 더 복잡하고 어려운 벤치마크가 등장하고 이를 통한 경쟁이 주를 이룰 것이고, 자체 인하우스 모델 사용이 중요한 경우는 모델 경량화와 같은 효율성 개선을 지속적으로 추구할 것으로 예상된다.
사실 체감상으로는 이미 모델 성능의 한계에 도달한 것이 아닐까 하는 생각도 든다. 이전 대비 버전이 바뀌더라도 큰 차이를 느끼기 어려운 상황이다. 몇 년 전만 해도 스마트폰이 매년 큰 발전을 이뤘지만, 지금은 해마다 스마트폰을 굳이 바꿀 필요가 없는 것처럼…