
VLM(Vision-Language Model) 기술 현황 : CLIP에서 LLaVA까지
Published:
📌 BLIP

1. 연구 주제와 주요 기여
BLIP는 Vision-Language Pre-training(VLP)을 위한 프레임워크로, 이미지와 텍스트 간의 이해 기반 작업과 생성 기반 작업을 모두 효과적으로 수행할 수 있도록 설계되었다.
기존 VLP 모델의 한계를 다음과 같이 개선했다.
- 이해 기반(예: 이미지-텍스트 검색) 또는 생성 기반(예: 이미지 캡션 생성) 작업에 특화된 기존 모델의 단점을 보완.
- 웹에서 수집된 노이즈가 많은 데이터로부터 학습 성능을 극대화하기 위한 데이터 부트스트래핑 방법 제안.
BLIP는 SOTA 성능을 기록하며 다양한 Vision-Language 작업에서 우수한 결과를 보였다.
2. 연구 배경과 관련 연구
Vision-Language Pre-training (VLP)
Vision-Language Pre-training(VLP)은 이미지와 텍스트를 함께 이해하고 활용하는 기술이다. 우리가 흔히 보는 이미지-텍스트 검색, 이미지 설명 생성 같은 작업에 꼭 필요한 기술이다. 그런데 기존 VLP 모델들은 대부분 웹에서 대규모로 수집한 이미지-텍스트 데이터를 학습했지만, 이 데이터가 노이즈가 많아서 문제였다. 데이터 품질이 좋지 않으면 모델이 잘못 학습되거나 성능이 떨어질 수 있으니까.
대표적인 기존 모델
- CLIP: 텍스트-이미지 검색에서 정말 뛰어난 성능을 보여줬지만, 텍스트를 만들어내는 작업에는 약했다.
- ALBEF: 이미지 속 디테일을 더 잘 활용했지만, 여전히 데이터의 노이즈 문제를 해결하지 못했다.
- SimVLM: 단순한 구조로 대규모 데이터를 잘 처리했지만, 한 가지 작업에만 특화된 느낌이었다.
기존 모델의 한계 기존 모델들은 각각의 작업에는 강점이 있지만, 이해와 생성 작업을 동시에 잘해내지 못하는 문제가 있었다.
- Encoder 기반 모델은 텍스트를 생성하기에는 적합하지 않아서 이미지 설명 같은 작업은 잘 못했다.
- Encoder-Decoder 기반 모델은 이미지-텍스트 매칭 같은 이해 작업에서 성능이 떨어짐.
또한, 웹에서 가져온 데이터의 노이즈 문제를 제대로 해결하지 못했기 때문에, 모델이 데이터의 오류나 불완전함까지 학습해버리는 일이 많았어요. 그래서 더 정교한 데이터 전처리 방법과 이해와 생성을 동시에 잘하는 모델이 필요했다.
3. 주요 제안
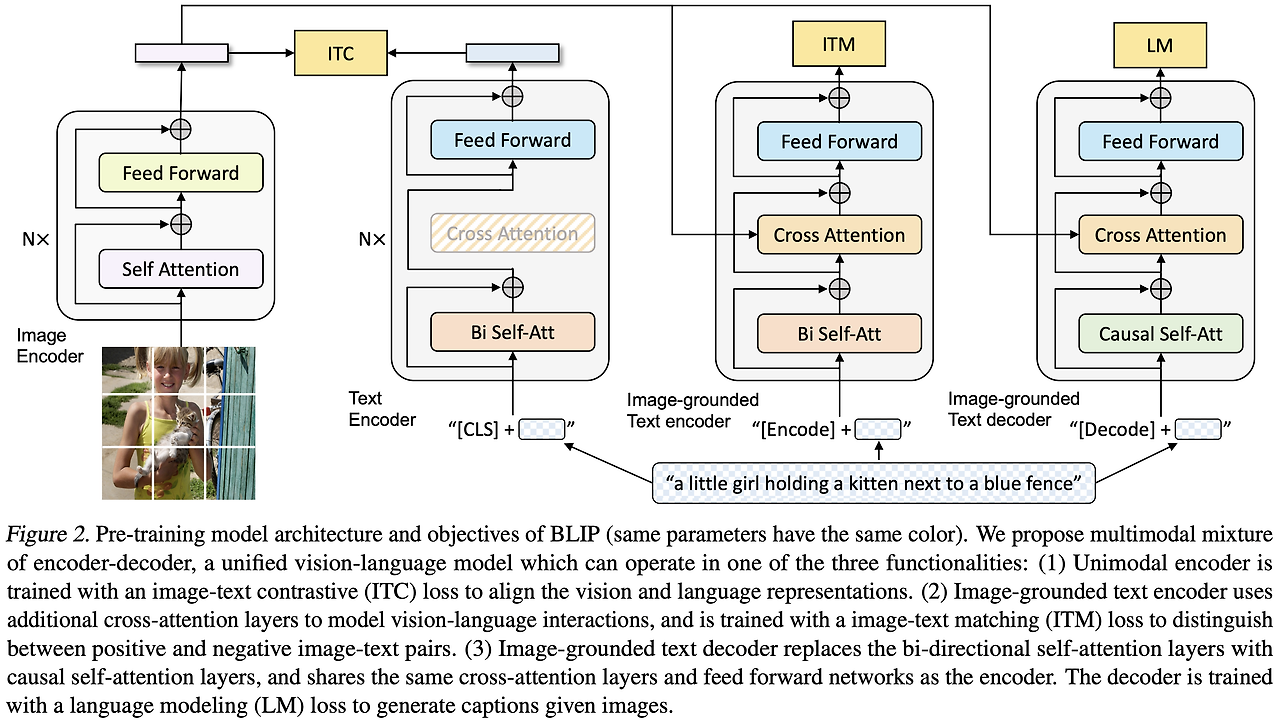
BLIP은 노이즈가 많은 이미지-텍스트 쌍을 효과적으로 학습할 수 있는 통합 비전-언어 프리트레이닝(VLP) 프레임워크를 제안한다. 이 프레임워크는 새로운 모델 아키텍처인 Multimodal Mixture of Encoder-Decoder (MED)와 데이터 품질을 개선하는 Captioning and Filtering (CapFilt) 방법론으로 구성됩니다.
3.1. Multimodal Mixture of Encoder-Decoder (MED)
BLIP의 핵심 구조인 Multimodal Mixture of Encoder-Decoder(MED)는 이해와 생성 작업을 동시에 수행할 수 있도록 설계된 다목적 비전-언어 모델이다. 이 아키텍처는 세 가지 모드로 구성되어 있으며, 각각 특정 작업의 요구사항을 충족하도록 설계되었다.
3.1.1. Unimodal Encoder
Unimodal Encoder는 이미지와 텍스트를 개별적으로 인코딩하여 각각의 표현 벡터를 생성한다. 텍스트 인코더는 BERT 아키텍처를 기반으로 하며, 입력 텍스트의 시작에 [CLS] 토큰을 추가해서 문장 전체를 요약하는 표현을 생성합니다. 이 모드는 이미지와 텍스트 각각의 독립적인 특징을 추출하는 데 적합한다.
3.1.2. Image-grounded Text Encoder
Image-grounded Text Encoder는 텍스트 인코더의 각 Transformer 블록에 크로스 어텐션(Cross-Attention) 계층을 추가한다. 이를 통해 이미지에서 얻은 정보를 텍스트 인코더에 통합하여 멀티모달 표현을 생성합니다. 이 모드는 이미지와 텍스트의 관계를 학습하는 데 중점을 두며, 이미지-텍스트 매칭과 같은 이해 기반 작업에서 활용된다.
3.1.3. Image-grounded Text Decoder
Image-grounded Text Decoder는 이미지를 기반으로 텍스트를 생성하는 모드이다. 디코더는 Causal Self-Attention을 사용하여 입력된 이미지의 정보를 바탕으로 순차적으로 텍스트를 생성합니다. 텍스트 생성을 시작하는 [Decode] 토큰과 종료를 나타내는 End-of-Sequence 토큰을 포함하며, 이미지 캡션 생성이나 텍스트 생성 작업에 적합합니다.
Vision Transformer (ViT) 활용 BLIP는 이미지 인코딩을 위해 Vision Transformer(ViT)를 사용한다. ViT는 이미지를 작은 패치 단위로 분할하고, 각 패치를 벡터 형태로 임베딩하여 Transformer 구조에 입력합니다. 이를 통해 시각적 정보를 효율적으로 학습하고, 다양한 이미지 작업에 활용할 수 있도록 지원한다.
3.2. Pre-training Objectives
MED 아키텍처는 이해와 생성 작업을 동시에 학습할 수 있도록 세 가지 Loss 함수를 사용해 학습됩니다.
3.2.1. Image-Text Contrastive Loss (ITC)
ITC는 이미지와 텍스트 간의 feature space를 정렬하기 위한 Loss입니다. 동일한 이미지-텍스트 쌍은 가까운 임베딩 공간에 위치하도록 학습하며, 그렇지 않은 쌍은 멀어지도록 조정한다. 또한, 모멘텀 인코더와 소프트 라벨을 활용해 잠재적 양성 샘플까지 학습에 포함하여 일반화 성능을 높였다.
예를 들어, “강아지가 공원에서 놀고 있는 사진”과 “강아지가 공원에서 놀고 있다”는 텍스트는 positive pair로 간주되며, 이 둘은 가까운 위치에 매핑된다. 반면, 같은 사진과 “바다에서 서핑을 즐기는 사람”이라는 텍스트는 negative pair로 간주되고 멀어지도록 학습됩니다.
이 Loss는 모델이 이미지와 텍스트의 관계를 이해하도록 도와 텍스트-이미지 검색이나 Zero-shot 작업 같은 태스크에서 유용하게 활용된다.
3.2.2. Image-Text Matching Loss (ITM)
ITM은 이미지와 텍스트가 실제로 매칭되는지를 이진 분류 방식으로 학습합니다. Hard Negative Mining 기법을 통해 유사하지만 매칭되지 않는 쌍을 구별하여 모델의 정교함을 높였다. 이 학습 목표는 이미지-텍스트 쌍의 세부적인 정합성을 평가하고 개선하는 데 초점이 맞춰져 있다.
예를 들어, “햇볕 아래 고양이가 낮잠을 자고 있는 사진”과 “고양이가 햇볕에서 자고 있다”는 텍스트는 positive pair로 학습됩니다. 반면, 비슷해 보이는 텍스트(“햇볕 아래에서 강아지가 자고 있다”)는 negative pair로 분류된다.
이 Loss는 이미지-텍스트 매칭, 이미지 설명 생성, 비주얼 질문 응답(VQA) 같은 작업에서 모델이 세부적인 관계를 잘 이해하도록 학습하는 데 핵심적인 역할을 한다.
3.2.3. Language Modeling Loss (LM)
LM은 이미지를 기반으로 텍스트를 생성하는 방법을 학습합니다. Autoregressive 방식으로 텍스트를 생성하며, label smoothing을 적용해 모델의 일반화 능력을 강화했다. 이를 통해 이미지 캡션 생성과 같은 작업에서 탁월한 성능을 보여줍니다.
예를 들어, “해변에서 사람이 서핑보드를 들고 있는 사진”이 주어졌다면, LM은 이를 기반으로 “한 사람이 해변에서 서핑보드를 들고 있다”와 같은 문장을 생성하도록 학습된다.
이 Loss는 이미지 캡션 생성 작업에서 탁월한 성능을 보여주며, Zero-shot 생성 작업에서도 활용된다.
각 Loss의 역할을 쉽게 요약하면
- ITC: 이미지와 텍스트가 서로 관련이 있는지 거리로 판단하는 학습
- ITM: 이미지와 텍스트가 정말 매칭이 되는지 이진적으로 판단하는 학습
- LM: 이미지를 보고 자연스러운 문장을 만들어내는 학습
학습 효율성 극대화 BLIP는 텍스트 인코더와 디코더가 Self-Attention 계층을 제외한 매개변수를 공유하도록 설계되었다. 이 공유 구조는 모델의 학습 효율을 크게 높이고, 이해와 생성 작업을 동시에 학습하는 데 필요한 리소스를 최소화합니다. 이를 통해 멀티태스킹 학습의 효과를 극대화할 수 있었다.
3.3. Captioning and Filtering (CapFilt): 데이터 부트스트래핑

BLIP는 CapFilt라는 두 단계의 데이터 부트스트래핑 기법을 사용해 웹에서 수집한 노이즈 많은 이미지-텍스트 데이터를 정제하고 활용했다.
3.3.1. Captioner
Captioner는 Image-grounded Text Decoder를 활용해 웹 이미지에서 합성 캡션(Synthetic Captions)을 생성한다. 생성된 캡션은 각 이미지에 하나씩 매칭되며, 데이터의 품질을 보강하는 데 기여합니다.
3.3.2. Filter
Filter는 Image-grounded Text Encoder를 사용하여 원본 웹 텍스트와 생성된 합성 캡션의 정합성을 평가합니다. ITM 헤드를 활용해 “비정합”으로 분류된 텍스트를 학습 데이터에서 제외하며, 데이터의 노이즈를 줄이고 학습 품질을 높였다
3.4. 모델 학습
BLIP 논문을 읽다보면 생각보다 학습 과정이 복잡한다. 학습 중에 데이터 부트스트래핑을 한다는 것인지, 이미 학습된 네트워크로 부트스트래핑을 한다는 것인지 헷갈린다…😥
논문을 보면 BLIP는 먼저 Text Encoder, Text Decoder가 포함된 MED를 대규모 노이즈가 포함된 웹 데이터셋으로 Pre-training합니다. 그 후, Pre-training이 완료된 MED 모델을 COCO와 같은 고품질의 소규모 데이터셋으로 Fine-tuning하여 Text Encoder와 Text Decoder를 더 정밀하게 학습시킵니다. 이렇게 Fine-tuning이 끝난 모델은 Text Encoder를 Filter로, Text Decoder를 Captioner로 사용하는 것입니다.
이제 Fine-tuning된 MED 모델을 활용해 데이터 부트스트래핑을 진행합니다. Captioner 역할을 하는 Text Decoder는 웹 이미지를 기반으로 새로운 합성 캡션을 생성하고, Filter 역할을 하는 Text Encoder는 기존의 웹 캡션과 새로 생성된 합성 캡션의 품질을 비교해 이미지와 더 잘 매칭되는 캡션을 선택합니다. 이 과정을 통해 기존의 노이즈가 많은 데이터 대신, 정제된 학습 데이터셋을 구축하게 됩니다.
마지막으로,부트스트래핑을 통해 새롭게 생성된 데이터셋을 사용하여 MED 모델을 다시 Pre-training합니다. 정제된 데이터셋을 기반으로 학습된 모델은 이전보다 더 높은 성능을 달성할 수 있습니다. Pre-training된 Text Encoder와 Text Decoder를 Captioner와 Filter로 활용해 새로운 학습 데이터셋을 생성하고, 이를 기반으로 모델을 다시 학습하는 방식은 다소 복잡하고 비효율적으로 보일 수 있지만, 노이즈가 많은 웹 데이터의 한계를 극복하고 점진적으로 데이터 품질과 모델 성능을 높이는 데 매우 효과적인 접근 방식이라고 볼 수 있습니다.
BLIP 학습 과정 간략 정리 💡
- 웹 데이터셋으로 MED pre-training
- 고품질 소규모 데이터셋으로 fine-tuning
- Fine-tuning 된 MED(Text Encoder/Decoder)로 데이터 부트스트래핑
- 부트스트래핑된 데이터셋으로 다시 pre-training
4. 주요 실험 내용 및 결과
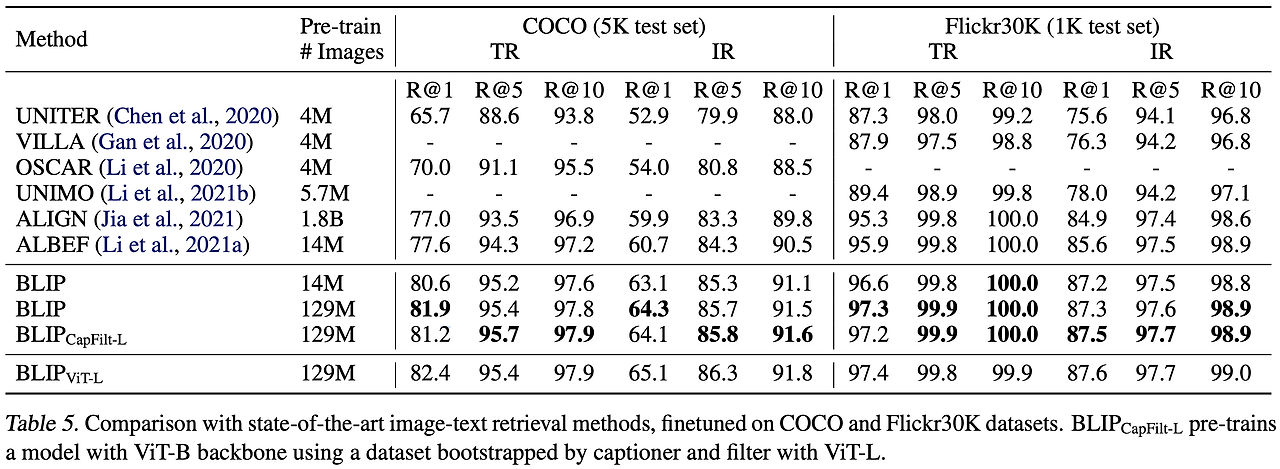
BLIP는 다양한 작업에서 기존 모델을 뛰어넘는 성능을 보여줬다. 먼저, 이미지-텍스트 검색 작업에서는 COCO 데이터셋 기준으로 ALBEF 대비 Recall@1에서 2.7% 향상된 결과를 기록했고, Zero-shot 설정에서도 뛰어난 일반화 성능을 보였다. 이미지 캡션 생성에서는 COCO와 NoCaps 데이터셋에서 CIDEr 점수 129.7을 달성하며 기존 모델 대비 더 높은 성능을 보여줬다. VQA(Visual Question Answering) 작업에서도 BLIP는 기존 최고 모델인 SimVLM(1.8B 데이터를 학습한 모델)을 능가하는 성능을 달성했으며, SimVLM보다 훨씬 적은 데이터(129M)로 학습했음에도 뛰어난 결과를 냈다. 마지막으로, Zero-shot 비디오 언어 작업에서도 비디오-텍스트 검색과 비디오 질문 응답에서 강력한 성능을 입증하며 다목적 비전-언어 모델로서의 가능성을 보여줬다.
5. 결론
BLIP는 이해와 생성 작업을 통합적으로 수행할 수 있는 Vision-Language Pre-training(VLP) 모델로, 기존 모델의 한계를 극복하며 다양한 작업에서 우수한 성능을 보여줬다. 특히, Multimodal Mixture of Encoder-Decoder(MED) 아키텍처와 Captioning and Filtering(CapFilt) 기법을 통해 데이터의 노이즈 문제를 해결하고 학습 효율성을 극대화했다. BLIP는 다목적성과 실용성을 강조하며 VLP 연구의 새로운 방향을 제시했지만, 다국어 지원과 데이터 품질 의존성 문제는 향후 연구에서 해결해야 할 과제로 남아 있다. 이를 통해 BLIP는 비전-언어 연구와 응용의 발전에 중요한 기반을 제공했다.
📌 BLIP-2
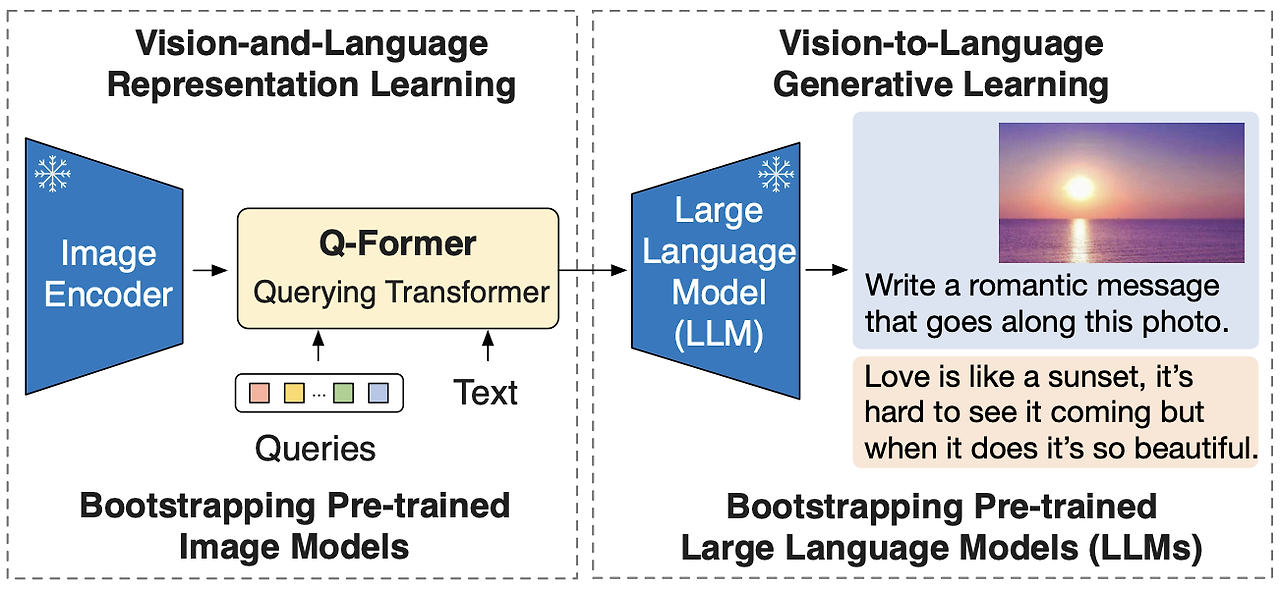
1. 연구 주제와 주요 기여
BLIP-2 논문은 Multi-modal Vision Language Pre-training(VLP)에 대한 비용 효율적인 새로운 접근법을 제안했다. 기존의 큰 모델을 end-to-end 로 학습시키는 방식의 높은 계산 비용을 해결하기 위해, 이미 학습된 이미지 인코더와 대형 언어 모델(LLM)을 고정(frozen)한 채로 사용하는 방법을 고안했다.
- Querying Transformer(Q-Former): Modality Gap(이미지와 텍스트 간의 차이)를 효과적으로 줄이기 위한 경량 모듈을 제안했다.
- Two-stage Pre-training: 기존 모델의 강점을 결합한 Representation Learning과 Generative Learning 전략으로 성능과 효율성을 모두 잡았다.
- Flamingo 등과 비교해 54배 적은 Trainable Parameters로도 최고 성능을 달성했다.
2. 연구 배경 및 동향
Vision-Language 연구는 이미지와 텍스트 간의 Representation 학습으로, Image Captioning, Visual Question Answering(VQA), Image-Text Retrieval 같은 작업에서 활발히 발전해왔다.
기존 CLIP(Radford et al., 2021)는 효율적인 Contrastive Learning 방식을 통해 강력한 Zero-shot 성능을 보여줬지만, Generative Task에서는 한계가 있었고, BLIP(Li et al., 2022)는 Contrastive와 Generative Task를 모두 지원했지만, 계산 비용이 많이 드는 문제가 있었다.
최근에는 Flamingo(Alayrac et al., 2022)처럼 Frozen Models를 활용하여 효율성을 높이는 방향으로 발전하고 있다.
3. 주요 제안
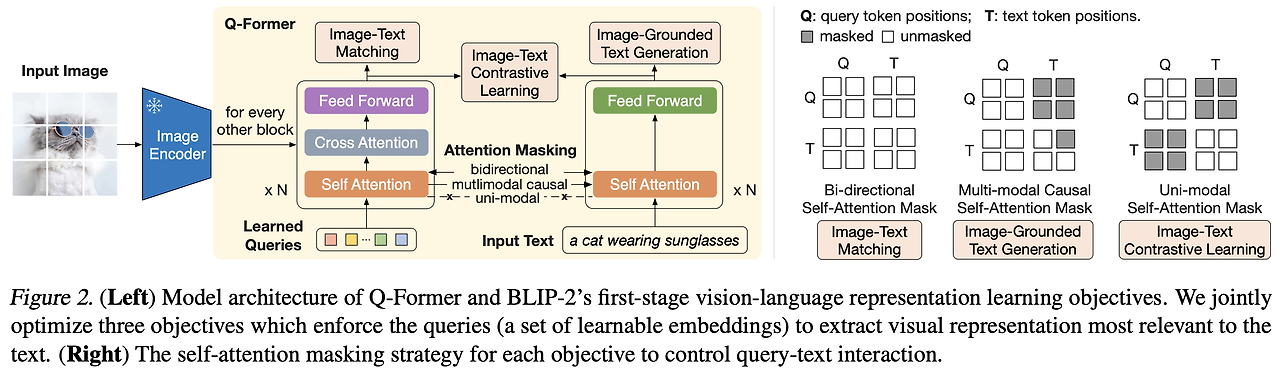
BLIP-2의 핵심은 Q-Former와 이를 기반으로 한 Two-stage Pre-training이다. 이 구조는 Frozen Image Encoder와 Frozen LLM 간의 Modality Gap(모달리티 격차)을 효율적으로 해소하고, 계산 자원을 아끼면서도 높은 성능을 구현할 수 있도록 설계되었다.
3.1. Q-Former
Q-Former는 Frozen Image Encoder와 Frozen LLM을 연결하는 경량 Transformer 모듈로, 두 모달리티 간의 정보를 효율적으로 교환하기 위해 설계되었다. 이 모듈은 다음과 같은 주요 기능을 수행한다.
3.1.1. Learnable Query Vectors
Q-Former는 Learnable Query Vectors라는 학습 가능한 벡터를 통해 이미지 인코더의 고정된 시각적 표현에서 가장 유용한 정보를 추출한다. 예를 들어, 이미지 인코더에서 257개의 이미지 특징 벡터를 출력했다면, Q-Former는 32개의 Query Vectors를 학습해 이 중 텍스트 생성에 필요한 핵심 정보만 요약해서 가져온다.
이 과정에서 Cross-Attention 메커니즘을 활용해 Query와 이미지 특징 간의 상호작용을 수행하며, 정보의 중요도를 판단해 필수적인 시각적 단서를 선택한다. 이 방식은 텍스트 생성과 같은 언어 작업에 필요한 정보만 선별적으로 전달하기 때문에, 모델의 효율성과 성능을 동시에 확보할 수 있다.
3.1.2. Bottleneck 역할
Q-Former는 이미지 인코더와 LLM 사이에서 정보 bottleneck 역할을 한다. 이미지 인코더가 출력하는 대규모의 시각 정보를 LLM이 효율적으로 처리할 수 있도록 필요한 핵심 정보로 간소화하는 데 중점을 둔다. 이 과정에서 Learnable Query Vectors를 활용해 필수적인 시각적 단서를 추출하고, 이를 LLM에 전달하여 텍스트 생성이나 질문 응답과 같은 작업을 수행할 때 필요한 최소한의 정보를 포함하도록 설계된다. 이렇게 정보의 양을 줄이면서도 중요한 내용을 놓치지 않도록 최적화함으로써 모델의 계산 자원을 절약하고 성능을 유지할 수 있다.
3.1.3. Transformer의 두 가지 모드
Q-Former는 이미지와 텍스트 간의 정보를 효과적으로 처리하기 위해 내부적으로 두 가지 모드의 Transformer를 포함하고 있다.
- Image Transformer: Learnable Query Vectors가 Frozen Image Encoder의 출력과 상호작용하여 이미지 데이터를 처리한다. 이 과정에서 이미지의 고정된 특징 표현에서 텍스트 생성에 필요한 시각적 정보를 선택적으로 추출한다.
- Text Transformer: Query Vectors가 Frozen LLM과 상호작용하며, 텍스트 생성이나 질문 응답에 필요한 정보를 전달한다. 이 과정에서 선택된 시각 정보는 자연어로 변환되는 데 사용된다.
이 두 가지 모드는 각각 시각 정보의 이해와 언어적 표현 간의 다리 역할을 하며, 두 모달리티의 격차를 줄이고 정보를 효율적으로 교환할 수 있도록 돕는다. 이러한 설계는 BLIP-2가 다양한 Vision-Language 작업에서 뛰어난 성능을 발휘하는 데 핵심적인 역할을 한다.
3.2. Two-stage Pre-training
BLIP-2는 Q-Former를 학습시키고 Vision-to-Language 작업을 최적화하기 위해 Representation Learning과 Generative Learning의 두 단계 Pre-training 전략을 사용한다. 이러한 전략은 계산 자원을 효율적으로 사용하면서도 높은 성능을 구현하도록 설계되었다.
3.2.1. Representation Learning
Representation Learning은 이미지와 텍스트 간 강력한 멀티모달 표현을 학습하는 첫 번째 단계이다. 이 단계는 이미지와 텍스트 사이의 관계를 정렬하고, 필요한 정보를 정확히 추출할 수 있도록 Q-Former를 학습하는 데 중점을 둔다. 주요 학습 목표는 다음과 같다.
1) Image-Text Contrastive Learning (ITC) ITC는 이미지와 텍스트를 벡터 공간에서 정렬(align)하는 작업이다. Q-Former의 Query Vectors는 이미지의 시각적 특징을 추출한 뒤, 이를 텍스트 표현과 비교해 positive pairs를 가까이, negative pairs를 멀리 위치하도록 학습한다.
예를 들어, “고양이가 선글라스를 쓰고 있는 이미지”와 “고양이가 선글라스를 쓰고 있다”는 텍스트는 positive pair로 간주된다. 반면, “강아지가 뛰어놀고 있는 이미지”는 negative pair로 처리된다.
이 작업을 통해 이미지와 텍스트 간 전반적인 의미적 일치를 학습한다.
2) Image-Text Matching (ITM) ITM은 이미지와 텍스트 간의 Fine-grained Alignment를 학습한다. 모델은 주어진 이미지와 텍스트 쌍이 일치하는지 여부를 이진 분류 방식으로 학습하고, 텍스트와 이미지 간의 세밀한 관계를 이해하도록 돕는다.
예를 들어, “사과”라는 텍스트와 “사과 사진”은 positive pair로 학습되지만, “바나나”라는 텍스트와 “사과 사진”은 negative pair로 학습된다.
이 과정은 모델이 텍스트와 이미지 간의 구체적이고 세밀한 맥락을 이해하도록 만든다.
3) Image-grounded Text Generation (ITG) ITG는 텍스트 생성에 필요한 시각적 정보를 추출하도록 Q-Former를 학습하는 과정이다. Query Vectors는 이미지에서 텍스트 생성에 필수적인 정보를 선별적으로 추출하고, 이를 텍스트 Transformer에 전달해 자연스러운 텍스트를 생성하도록 학습한다.
예를 들어, 사진 설명 생성 작업에서 “이 사진은 선글라스를 쓴 고양이를 보여준다”와 같은 텍스트를 생성하도록 학습한다.
Representation Learning의 의미
Representation Learning은 LLM이 처리해야 할 시각 정보의 양을 줄이고, Q-Former가 최적화된 시각 표현을 LLM에 전달할 수 있도록 학습하는 기초 단계이다. 이를 통해 Frozen Image Encoder와 Q-Former 간 협력을 강화하고, 텍스트 생성에 필요한 시각적 정보를 효율적으로 정렬한다.
3.2.2. Generative Learning: 텍스트 생성 최적화
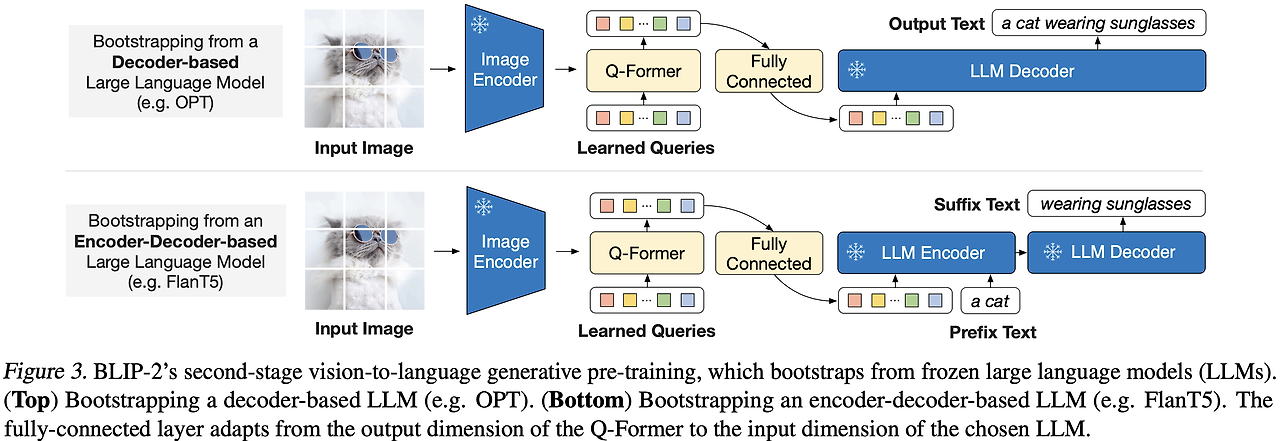
Generative Learning은 Representation Learning 이후 진행되는 두 번째 단계로, LLM과의 연결을 최적화해 텍스트 생성 능력을 강화하는 데 초점을 맞추고 있다. 이 단계는 LLM이 시각 정보를 자연어로 변환하는 과정을 정교하게 조율한다.
1) Soft Prompting with Q-Former Q-Former는 Frozen LLM과 직접 연결되지 않고, Query Representation을 Soft Prompt로 변환해 LLM의 입력으로 제공한다. 이 방식은 LLM의 구조나 가중치를 변경하지 않으면서도, 시각적 정보를 텍스트로 표현하는 능력을 자연스럽게 강화한다.
예를 들어, 이미지에서 추출한 Query Representation을 “이미지 설명:”이라는 텍스트와 결합해 입력하면, LLM이 “고양이가 선글라스를 쓰고 있다”와 같은 문장을 생성하도록 유도한다.
2) Decoder-based LLM (OPT)와 Encoder-Decoder LLM (FlanT5)의 차이
OPT (Decoder-only) Query Representation은 LLM의 입력 텍스트에 앞에 붙는 추가 토큰처럼 동작한다. (예시: “이미지 설명: 고양이가 선글라스를 쓰고 있다.”)
FlanT5 (Encoder-Decoder) Query Representation은 LLM의 인코더 입력과 결합돼 텍스트 생성 과정을 돕는다. (예시: “이미지 설명 생성 -> 텍스트 출력.”)
Generative Learning의 의미
Generative Learning은 Q-Former가 추출한 시각 정보를 Frozen LLM에 효과적으로 전달하고, 이를 기반으로 자연스러운 텍스트를 생성하는 능력을 최적화하는 단계이다. 이 접근법은 LLM의 구조를 변경하지 않으면서도 강력한 Vision-to-Language 성능을 구현할 수 있도록 돕는다.
3.2.3. Two-Stage Pre-training의 강점
Representation Learning과 Generative Learning의 조합은 BLIP-2가 적은 Trainable Parameters로도 높은 성능을 달성할 수 있도록 해준다.
- Frozen Models을 활용해 최신 모델의 강점을 최대한 활용하면서 계산 자원을 절약한다.
- Q-Former는 Vision-to-Language 작업에서 필수적인 정보만 선별적으로 전달해 효율성을 극대화한다.
- 이러한 접근은 시각적 데이터를 효과적으로 언어적 표현으로 변환하는 데 최적화되어, 다양한 Vision-Language 작업에서 뛰어난 성능을 발휘한다.
BLIP-2의 Two-Stage Pre-training 전략은 Vision-Language 연구의 새로운 기준을 제시하며, 효율성과 성능의 완벽한 균형을 보여준다.
4. 실험 결과

BLIP-2는 다양한 Vision-Language 작업에서 뛰어난 성능을 입증하며, 효율성과 정확성을 동시에 보여줬다. Zero-shot VQA 작업에서 Flamingo80B 대비 8.7% 더 높은 정확도(65.0%)를 기록했으며, 이는 54배 적은 Trainable Parameters로 달성된 결과로 모델의 경량화와 효율성을 잘 보여준다. 이미지 설명 생성에서는 COCO와 NoCaps 데이터셋에서 각각 CIDEr 점수 145.8과 121.6으로 최고 성능을 기록하며, 이미지의 시각적 정보를 자연스러운 텍스트로 변환하는 능력을 입증했다. 또한, 이미지-텍스트 검색에서는 Flickr30K와 COCO 데이터셋에서 Recall@1 기준 각각 97.6%와 85.4%를 달성하며, 텍스트와 이미지 간의 관계를 정교하게 이해하는 모델의 강점을 보여줬다. 이러한 결과는 BLIP-2가 적은 자원으로도 높은 성능을 구현하며, 다양한 Vision-Language 작업에서 다목적성과 일반화 능력을 갖춘 모델임을 나타낸다.
5. 결론
BLIP-2는 멀티모달 AI에서 계산 효율성과 성능을 혁신적으로 결합한 모델로, Q-Former를 활용해 고정된 이미지 및 언어 모델 간의 간극을 효과적으로 해소하며 새로운 가능성을 열어줬다. 고정된 언어 모델(OPT, FlanT5 등)에 의존하는 만큼 선택한 언어 모델의 품질이 성능에 영향을 미치고, 다중 이미지-텍스트 시퀀스 데이터 세트 부족으로 인해 in-context learning 성능이 제한적이라는 한계도 있지만, 이러한 문제는 더 풍부한 데이터와 모듈 개선을 통해 충분히 보완 가능성이 있다.
BLIP-2는 CLIP과 BLIP의 강점을 모두 이어받으면서도 효율성을 극대화한 점이 돋보이며, 실용성과 확장성 측면에서 멀티모달 AI의 새로운 기준을 제시했다.
📌 LLaVA

1. 연구 주제와 주요 기여
이 연구는 텍스트와 이미지를 함께 이해하고 처리할 수 있는 멀티모달 모델 LLaVA를 제안하고 있다. 특히 Visual Instruction Tuning을 통해 멀티모달 작업에서 사용자의 지시를 따르고, 복잡한 이미지와 텍스트 기반 작업을 수행할 수 있도록 모델을 설계했다. 기존의 이미지-텍스트 페어 데이터(예: COCO)를 활용한 학습에서 한 발 더 나아가, GPT-4를 활용해 이미지 설명 캡션을 바탕으로 질문과 답변 형식의 새로운 학습 데이터를 생성했다.
- 새로운 데이터셋 생성 방법: GPT-4를 활용해 기존 이미지-텍스트 페어를 멀티모달 지시-응답 데이터로 자동 변환하는 데이터 생성 파이프라인을 개발했다. 이를 통해 다양한 멀티모달 작업에 활용 가능한 학습 데이터를 구축했다.
- 새로운 멀티모달 모델 제안: CLIP 기반의 비전 인코더와 Vicuna 기반의 언어 모델을 연결해 LLaVA 모델을 설계했다. 이를 통해 이미지와 텍스트 간의 깊은 상호작용을 가능하게 했다.
- 멀티모달 작업에서 모델 성능을 평가하기 위한 새로운 벤치마크 LLaVA-Bench를 제공한다. 이를 통해 모델의 성능을 정량적으로 평가할 수 있었다.
2. 연구 배경과 동향
기존 멀티모달 연구는 주로 각각의 작업(예: 이미지 분류, 캡션 생성)을 별도의 모델로 해결하는 데 초점을 맞췄으며, 언어는 보조적인 역할(예: 이미지를 설명)로 사용되었다. 하지만 최근 GPT-4와 같은 LLM이 등장하면서, 언어를 보편적 인터페이스로 활용해 다양한 작업을 단일 모델로 처리할 수 있는 가능성을 보여줬다.
- LLM 튜닝: ChatGPT와 LLaMA 같은 텍스트 기반 LLM에서 Instruction Tuning이 일반적인 작업 수행 능력을 크게 향상시키는 모습을 보여줬다. 이는 LLM을 다양한 태스크에 적용할 수 있는 강력한 도구로 자리 잡게 했다.
- 멀티모달 모델 개발: 기존의 멀티모달 모델(예: BLIP-2, Flamingo, OpenFlamingo)은 멀티모달 작업에서 의미 있는 성과를 보였지만, 대부분 비전-언어 지시 데이터를 활용한 튜닝이 부족해서 작업 일반화 성능에 한계를 보였다.
- LLaVA는 비전-언어 지시 데이터를 활용해 모델을 튜닝하고, 기존 멀티모달 모델보다 더 높은 작업 일반화를 목표로 했다. 이는 단순히 이미지를 설명하거나 텍스트를 생성하는 수준을 넘어, 사용자의 지시를 수행하고 다양한 멀티모달 태스크를 처리할 수 있는 모델을 만들기 위한 접근이다.
3. 주요 제안
3.1. 데이터 생성
LLaVA는 멀티모달 모델을 학습시키기 위해 GPT-4와 ChatGPT를 활용해 Vision-Language Instruction-following 데이터를 생성했다. 이 과정에서 기존의 이미지-텍스트 페어 데이터를 바탕으로 다양한 질문과 답변 형식의 학습 데이터를 자동 생성하는 방법론을 제시했다.
3.1.1. 학습 데이터 생성 방법
LLaVA는 멀티모달 학습을 위해 GPT-4를 활용해 기존 이미지-텍스트 페어 데이터를 바탕으로 대화형 데이터(Conversation), 상세 묘사(Detailed Description), 복잡한 추론(Complex Reasoning)이라는 세 가지 유형의 학습 데이터를 생성했다. 각 유형은 서로 다른 수준의 텍스트-이미지 이해와 처리를 요구한다.
1) 대화형 데이터 (Conversation) 대화형 데이터는 사용자와 AI 간의 상호작용을 모방하여 질문과 답변의 형태로 구성되었다. 예를 들어, 사용자가 이미지를 보면서 “이 사진 속에 있는 동물은 무엇인가요?”라고 묻는다면, 모델은 “사진 속에는 한 마리의 고양이가 있습니다.”라는 응답을 생성하도록 학습한다. 이 데이터는 AI가 사용자의 질문에 자연스럽게 응답할 수 있는 능력을 키우는 데 도움을 준다.
- 질문: “이 이미지에서 사람이 무엇을 하고 있나요?”
- 답변: “사람들이 SUV에 짐을 싣고 있는 모습입니다.”
2) 상세 묘사(Detailed Description) 상세 묘사는 이미지를 가능한 한 자세히 묘사하는 서술형 데이터로 구성되었다. 모델이 이미지의 모든 시각적 요소를 인식하고 이를 텍스트로 설명하는 데 중점을 둔다. 예를 들어, 단순히 “사람들이 SUV 옆에 서 있다”는 묘사에서 더 나아가, “검은색 SUV 옆에서 세 사람이 서로 이야기를 나누며 짐을 정리하고 있다”와 같은 구체적인 설명을 생성하도록 학습했다.
- 예시 묘사: “사진에는 검은색 SUV가 있고, 세 명의 사람이 짐을 정리하고 있습니다. 차량 옆에는 커다란 여행 가방과 작은 핸드백이 놓여 있으며, 하늘은 맑은 상태입니다.”
3) 복잡한 추론(Complex Reasoning) 복잡한 추론 데이터는 단순히 이미지를 묘사하는 데 그치지 않고, 이미지를 기반으로 한 논리적 사고와 이유를 요구하는 질문과 답변으로 구성되었다. 이 데이터는 AI가 추론을 통해 응답을 생성하는 능력을 학습하는 데 사용된다. 예를 들어, “이 사람들이 여행을 떠날 준비를 하고 있는 이유는 무엇인가요?”라는 질문에 “짐을 SUV에 싣는 모습으로 보아, 가족 여행을 준비하는 것 같습니다.”와 같은 응답을 생성할 수 있도록 훈련했다.
- 질문: “이 사진에서 사람들이 어떤 감정을 느끼고 있을까요?”
- 답변: “사람들이 함께 대화를 나누며 웃고 있는 모습으로 보아, 긍정적이고 행복한 감정을 느끼고 있는 것 같습니다.”
3.1.2. 왜 텍스트 데이터만을 사용했을까?
LLaVA는 텍스트 기반 캡션과 바운딩 박스 정보를 활용해 데이터를 생성했는데, 이를 선택한 이유는 텍스트 전용 모델의 구조적 제한과 비용 효율성 때문이다. GPT-4와 ChatGPT는 텍스트 기반 모델로, 이미지 데이터를 직접 처리할 수 없어서 이미지를 텍스트로 변환한 데이터를 사용해야 했다. 예를 들어, 이미지를 “A black SUV surrounded by luggage”와 같은 텍스트 캡션 형태로 표현하거나, “사람, 가방, 차량 등의 위치와 범위”를 숫자로 표시한 바운딩 박스 데이터를 제공했다.
또한, 이미지 데이터를 포함한 학습 데이터셋을 수작업으로 생성하는 것은 비용이 매우 크고 시간이 오래 걸린다. 반면, 기존 텍스트 기반 이미지 설명 데이터를 활용하면 대규모 데이터를 빠르고 저렴하게 증강할 수 있었다. GPT-4는 텍스트 기반 입력만으로도 뛰어난 추론 능력을 발휘할 수 있기 때문에, 캡션이나 바운딩 박스 정보만으로도 논리적이고 상세한 질문-응답 데이터를 만들어낼 수 있었다.
3.1.3. 저자가 강조한 포인트
이 논문에서는 텍스트 데이터를 기반으로 한 데이터 생성 방법론의 실용성과 효율성을 강조했다. 이미지를 포함하지 않고도 기존의 텍스트 데이터를 활용해 다양한 멀티모달 학습 데이터를 생성할 수 있음을 보여줬다. 특히, GPT-4의 강력한 언어 처리 및 추론 능력을 통해 단순 캡션만으로도 고품질의 질문-응답 데이터를 만들어냈다.
또한, 텍스트만을 사용한 데이터 증강 방법은 데이터 다양성과 확장 가능성을 높이는 데 유리했다. 다양한 캡션 데이터와 바운딩 박스 정보를 활용해 더 많은 유형의 질문-응답 데이터를 자동으로 생성할 수 있었다. 마지막으로, 저자들은 텍스트 기반 학습의 실용성을 입증하면서도, 향후 텍스트와 이미지를 함께 활용하는 방식으로 발전할 가능성을 열어두었다. 현재는 텍스트 중심으로 학습 데이터를 생성했지만, 더 복잡한 시각 정보 통합은 미래 연구 과제로 남아 있다.
3.2. Model Architecture
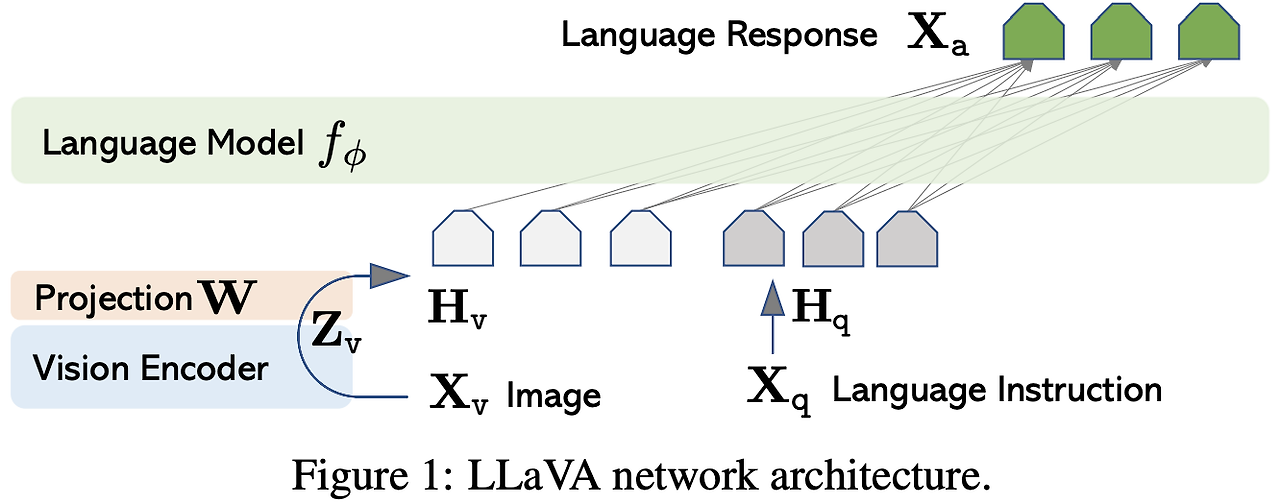
LLaVA의 모델 아키텍처는 간단하면서도 강력하게 설계되어, 사전 학습된 LLM(Vicuna)과 비전 모델(CLIP ViT-L/14)을 효과적으로 연결한다. 이를 통해 이미지와 텍스트 간의 상호작용을 효율적으로 수행하며 멀티모달 작업에서 뛰어난 성능을 보여줬다. 주요 구성 요소는 다음과 같다.
3.2.1. Vision Encoder (CLIP 기반)
Vision Encoder는 이미지를 이해하고 이를 시각적 특징으로 변환하는 역할을 한다. LLaVA에서는 사전 학습된 CLIP 모델의 ViT-L/14를 사용했다. 이 모델은 입력 이미지 $X_v$를 받아 시각적 특징 $Z_v$로 변환하며, 이 과정에서 이미지를 grid 형태의 비주얼 토큰으로 나타낸다. Vision Encoder는 사전 학습된 상태로 frozen되어 있으며, 학습 과정에서 가중치가 업데이트되지 않는다. 이를 통해 이미지 처리 성능을 유지하면서 학습 효율성을 높였다.
3.2.2. Projection Layer
Projection Layer는 CLIP에서 생성된 비주얼 특징 $Z_v$를 LLM(Vicuna)이 이해할 수 있는 언어 임베딩 공간으로 변환한다. 이 선형 레이어는 사전 학습된 이미지 특징을 언어 모델의 단어 임베딩 공간에 맞춰 매핑하는 역할을 하며, 다음 수식으로 표현된다.
\[H_v = W \cdot Z_v\]여기서 $W$는 학습 가능한 매개변수인 투영 행렬이고, $H_v$는 언어 임베딩 공간에서 시각적 특징을 나타내는 비주얼 토큰이다. Projection Layer는 경량 설계로 빠른 학습과 데이터 실험을 반복적으로 수행할 수 있는 장점을 제공했다.
3.2.3. Language Decoder (Vicuna 기반)
LLaVA의 Language Decoder는 사전 학습된 Vicuna를 사용하며, GPT 계열의 언어 모델과 유사한 구조를 가지고 있다. Vicuna는 강력한 인스트럭션 추론 성능을 통해 이미지에서 전달받은 시각적 정보를 바탕으로 자연스러운 텍스트 응답을 생성한다. Projection Layer에서 전달된 비주얼 토큰 $H_v$와 텍스트 입력을 동일한 시퀀스로 결합하여 학습한다. 예를 들어, “이미지 설명: “과 같은 텍스트와 $H_v$를 결합해 질문에 대한 응답을 생성할 수 있다.
이 모델은 언어 토큰과 비주얼 토큰을 동일한 시퀀스로 처리하면서, 멀티모달 정보의 통합을 효과적으로 수행한다. 이를 통해 텍스트 생성뿐 아니라, 질문-응답이나 복잡한 추론 작업에서도 뛰어난 성능을 발휘했다.
3.3. 학습 과정
LLaVA의 학습 과정은 Pre-training과 Fine-tuning의 두 단계로 구성되어 있다. 이 접근법은 사전 학습된 Vision Encoder와 LLM을 효과적으로 활용하며, 학습 효율성을 극대화했다.
3.3.1. Pre-training
첫 번째 단계에서는 Vision Encoder와 LLM 간의 기본적인 호환성을 학습하기 위해, 필터링된 59만 개의 이미지-텍스트 페어(CC3M)를 사용했다. 이 단계에서 Projection Layer만 학습되며, Vision Encoder와 LLM은 모두 frozen된 상태로 유지된다.
이 과정에서 입력 이미지 $X_v$를 시각적 특징 $Z_v$로 변환한 뒤, Projection Layer를 통해 언어 임베딩 공간으로 매핑했다. 질문과 답변 데이터를 생성해 LLM이 이미지 정보를 언어적으로 이해할 수 있도록 학습했다. 예를 들어, 질문 “이 이미지에 무엇이 보이나요?”에 대해 캡션 “검은 SUV가 짐을 싣고 있는 모습”을 정답으로 사용했다. 이 단계는 LLaVA가 이미지 정보를 언어 임베딩과 정렬시키는 데 초점을 맞췄다.
3.3.2. Fine-tuning
Fine-tuning 단계에서는 GPT로 생성한 세 가지 유형의 학습 데이터(대화형 데이터, 상세 묘사, 복잡한 추론)로 구성된 멀티모달 데이터셋(158,000개)을 활용해 LLaVA를 정밀하게 학습했다. Fine-tuning 과정에서는 Projection Layer와 LLM(Vicuna)의 가중치를 함께 업데이트하며, 모델이 시각적 정보와 텍스트를 긴밀히 통합할 수 있는 능력을 학습했다.
Fine-tuning 단계에서는 대화형 데이터, 상세 묘사 데이터, 복잡한 추론 데이터를 활용해 모델의 다양한 작업 수행 능력을 학습시켰다. 대화형 데이터는 멀티턴 대화를 학습해 사용자 질문에 자연스럽게 응답하는 능력을 강화했고, 상세 묘사 데이터는 이미지의 시각적 세부 정보를 텍스트로 표현하도록 모델을 학습했다. 또한, 복잡한 추론 데이터는 모델이 이미지의 맥락을 이해하고 심화된 논리적 질문에 답변할 수 있는 능력을 학습하도록 설계되었다.
이러한 Fine-tuning 전략은 LLaVA가 사용자 지시에 따라 자연스럽고 논리적인 응답을 생성할 수 있도록 설계된 중요한 학습 단계이다.
LLaVA의 모델 아키텍처는 단순하면서도 효율적인 설계를 통해 사전 학습된 강력한 Vision Encoder와 LLM을 연결했다. 경량 Projection Layer를 통해 빠른 학습과 데이터 실험이 가능했으며, Pre-training과 Fine-tuning 단계를 통해 이미지와 텍스트 간의 조화를 효과적으로 학습했다. 이 아키텍처는 다양한 멀티모달 작업에서 높은 성능을 발휘했다.
4. 실험 결과

LLaVA는 다양한 평가에서 멀티모달 모델로서 뛰어난 성능을 입증했다. COCO 데이터셋 기반 평가에서는 90개의 질문을 활용해 모델의 지시 수행 능력을 평가했으며, 세 가지 질문 유형 모두에서 GPT-4에 비해 85.1%의 상대 점수를 기록했다. 이는 LLaVA가 다양한 유형의 질문에 대해 일관되게 높은 정확도를 보여줬다는 것을 의미한다.
In-the-Wild 평가에서는 실내외 이미지, 밈, 스케치 등 다양한 도메인의 24개 이미지와 질문으로 모델을 테스트했다. 이 평가에서 LLaVA는 BLIP-2 대비 29%, OpenFlamingo 대비 48% 더 높은 성능을 기록하며, 다양한 시각적 표현과 문맥에서도 강력한 적응력을 보여줬다. 이러한 결과는 LLaVA가 기존 멀티모달 모델을 넘어서는 일반화 능력을 가지고 있음을 나타낸다.
또한, Science QA 데이터셋에서는 멀티모달 과학 질문 응답에서 90.92%의 정확도를 달성하며 새로운 SOTA(State-of-the-Art) 성능(92.53%)에 근접했다. 이는 LLaVA가 과학적 추론을 포함한 복잡한 문제 해결에서도 우수한 성과를 보여준다는 것을 입증했다.
5. 결론
LLaVA는 텍스트와 이미지를 통합적으로 이해하며, 사용자의 지시에 따라 자연스러운 응답을 생성할 수 있는 새로운 차원의 멀티모달 AI 모델이다. GPT-4를 활용한 데이터 생성과 효과적인 튜닝 전략을 통해 다양한 멀티모달 작업에서 높은 정확도와 유연성을 보여주며, 멀티모달 AI의 새로운 가능성을 열었다.
LLaVA의 강점은 다양한 도메인과 작업에서 뛰어난 성능을 발휘한다는 점이다. 특히, COCO 데이터셋과 In-the-Wild 평가, 그리고 Science QA 데이터셋에서 입증된 결과는 모델의 일반화 능력과 실용성을 잘 보여준다. 하지만 이미지의 고해상도 세부 정보 처리나 지식 범위와 같은 부분에서는 여전히 개선의 여지가 있다. 이는 멀티모달 AI 모델이 앞으로 더 깊고 세밀한 정보를 다룰 수 있도록 발전할 가능성을 시사한다.
📌 VLM(Vision-Language Model) 기술의 발전과 현황
Vision-Language Model(VLM)은 이미지를 이해하고 텍스트로 표현하거나, 텍스트와 이미지를 통합적으로 처리하는 AI 기술로, 지난 몇 년간 빠른 발전을 이루었다. CLIP, BLIP, BLIP-2, 그리고 LLaVA와 같은 주요 모델들은 각각의 접근 방식을 통해 VLM 기술의 범위를 확장하고 새로운 가능성을 열어줬다.
VLM 기술의 발전
VLM(Vision-Language Model) 기술은 초기에는 이미지와 텍스트 간의 Representation Alignment에 초점을 맞췄다. 대표적으로 CLIP은 이미지와 텍스트를 같은 벡터 공간에 매핑해 서로 잘 맞는 쌍을 찾는 데 강점이 있었다. 이를 통해 텍스트-이미지 검색과 같은 작업에서 뛰어난 성능을 보여줬지만, 텍스트 생성이나 이미지의 세부적인 내용을 설명하는 생성 기반 작업에는 한계가 있었다.
이후 등장한 Flamingo는 이러한 한계를 개선하기 위해 Gated Cross-Attention 메커니즘을 도입해 텍스트와 이미지 간의 상호작용을 강화했다. Flamingo는 Few-shot Learning 능력이 강해 소량의 데이터로도 새로운 작업에 적응할 수 있었으며, 대화형 질문 응답과 이미지 설명 생성에서 좋은 성능을 보여줬다. 하지만 대규모 데이터와 계산 자원이 필요한 구조적 한계가 있었다.
비슷한 시기에 등장한 SimVLM(Simple Visual Language Model)은 간단한 구조를 통해 대규모 이미지-텍스트 데이터를 효과적으로 처리하며 텍스트 생성 작업에 특화된 모델로 주목받았다. SimVLM은 이미지 설명 생성과 같은 작업에서 높은 성능을 보였지만, 세부적인 시각적 정보를 처리하는 능력에는 약간의 한계가 있었다.
다음으로, Google의 PaLI(Pathways Language and Image Model)는 멀티모달 작업을 넘어 다국어 지원까지 포함하며 기술을 한 단계 더 발전시켰다. PaLI는 이미지 캡션 생성, 텍스트 번역, VQA(Visual Question Answering) 작업에서 뛰어난 성능을 보여주었으며, 특히 여러 언어를 지원해 다국어 멀티모달 작업에서 강력한 도구로 자리 잡았다. 하지만 대규모 모델로 인해 학습과 추론에 많은 자원이 필요하다는 한계가 있었다.
이후 BLIP은 Generative Learning을 추가하며 한 단계 더 발전했다. 이미지 설명 생성(Image Captioning)과 VQA(Visual Question Answering)와 같은 작업에서도 좋은 성능을 보였지만, 계산 비용이 크고 효율성이 부족하다는 점이 단점으로 지적되었다. 이를 개선한 BLIP-2는 Two-stage Learning(Representation + Generative) 방식을 통해 효율성과 성능의 균형을 맞추며, CLIP과 BLIP의 장점을 결합했다. 특히, Q-Former를 도입해 고정된 이미지 및 언어 모델(Frozen Models)을 효과적으로 연결함으로써 최소한의 학습 매개변수로도 뛰어난 성능을 달성했다. 하지만 여전히 Frozen Models에 의존한다는 점은 단점으로 남아 있다.
그 이후 등장한 LLaVA는 단순히 이미지와 텍스트를 연결하는 것을 넘어 사용자의 지시 수행 능력에 초점을 맞췄다. LLaVA는 단순한 이미지 설명을 넘어, 대화(conversation)와 복잡한 논리적 추론(complex reasoning)을 수행할 수 있는 능력을 갖췄다. 예를 들어, CLIP이 “이 이미지는 고양이다”라고 판단할 수 있는 반면, LLaVA는 “고양이의 색깔, 행동, 배경”에 대해 사용자와 대화할 수 있는 모델이다.
LLaVA는 멀티모달 작업에서 효율성과 유연성을 동시에 확보했다. GPT-4를 활용한 데이터 생성과 Visual Instruction Tuning 전략을 통해 대화, 이미지 설명, 질문-응답과 같은 복합적인 작업을 수행할 수 있었다. 이러한 발전은 VLM 기술이 단순히 이미지와 텍스트를 연결하는 수준에서 벗어나, 지시를 이해하고 상호작용을 수행할 수 있는 방향으로 확장되고 있음을 잘 보여준다.
현재 VLM 기술의 트렌드
효율성과 성능의 균형: BLIP-2와 LLaVA는 최소한의 학습 매개변수와 계산 자원으로도 SOTA 성능을 달성하며, 효율성을 중요하게 고려하고 있다. 경량화된 설계는 학습 및 실무 적용에서 큰 장점으로 작용하고 있다.
멀티모달 대화 및 상호작용: LLaVA는 사용자의 지시를 이해하고 이를 바탕으로 대화를 나누거나 질문에 논리적인 응답을 생성하는 능력을 보여줬다. 이는 단순한 이미지-텍스트 매핑을 넘어, AI가 인간과 상호작용하며 작업을 수행할 수 있는 방향으로 기술이 발전하고 있음을 나타낸다.
도메인 일반화 능력: In-the-Wild 평가에서 LLaVA가 보여준 뛰어난 성능처럼, VLM 기술은 다양한 도메인(예: 실내외 이미지, 밈, 스케치 등)에서 높은 적응력을 가지는 방향으로 발전하고 있다.
Instruction Tuning: GPT-4와 같은 LLM의 강력한 추론 능력을 활용해, Vision-Language 모델에서도 사용자의 지시를 따르는 능력을 갖추는 것이 최신 트렌드로 자리 잡고 있다. 이는 AI가 점점 더 인간의 요구에 맞는 정교한 작업을 수행하도록 만드는 데 중요한 역할을 하고 있다.
VLM 기술의 미래
VLM은 단순한 이미지-텍스트 매핑을 넘어서, 점점 더 이미지의 복잡한 형태를 이해하고 분석하는 방향으로 발전할 것으로 기대된다. 예를 들어, 이미지 내의 세부적인 시각적 요소를 더 정밀하게 구분하거나, 객체 간의 관계를 이해하는 능력이 향상될 거이다. 이를 통해 모델은 단순히 “이것은 고양이입니다”를 넘어 “고양이가 창문 옆에서 바깥을 내다보고 있는 상황입니다”와 같은 복잡한 설명을 생성할 수 있을 겁니다.
또한, VLM 기술은 더 길고 복잡한 프롬프트를 이해하는 방향으로도 발전하고 있다. 예를 들어, “이 사진의 배경에 보이는 모든 건축물의 특징을 나열하고, 중앙에 있는 사람의 행동과 그 의미를 설명해주세요”와 같은 복잡한 지시를 수행할 수 있는 모델이 등장할 것으로 예상된다. 이러한 발전은 AI가 인간의 요구를 더욱 정교하게 이해하고 응답할 수 있도록 만들어줄 것이다.
결론적으로, CLIP에서 시작해 BLIP, BLIP-2, 그리고 LLaVA로 이어지는 발전은 VLM 기술이 단순한 이미지와 텍스트 간의 매핑을 넘어, 지시 수행, 상호작용, 복잡한 분석, 그리고 다양한 도메인에 적응하는 능력을 중심으로 빠르게 발전하고 있음을 보여준다.