
[Project] 이미지 분류 모델 효율적으로 개발하기
Published:
이번 포스팅에서는 2024년 초에 진행한 이미지 분류 모델 개발 프로젝트를 소개한다. 단, 회사 내부 데이터・지표・시스템 구현 등 기밀에 해당할 수 있는 정보는 모두 제외하고, ML 모델링 관점의 핵심 아이디어와 학습 설계만 간략히 정리한다.
본 프로젝트는 딥러닝 기술을 활용해 데이터 구축부터 모델 학습까지의 전 과정을 다루며, 서비스에 사용되는 이미지를 약 10개의 카테고리로 분류하는 작업을 수행했다. 특히, Zero-shot 분류와 OOD(Out-of-Distribution) 필터링 기법을 활용해 데이터 처리 시간을 단축하고 모델 성능을 개선했던 방법들을 중점적으로 설명한다.
1. 이미지 분류 모델 선정
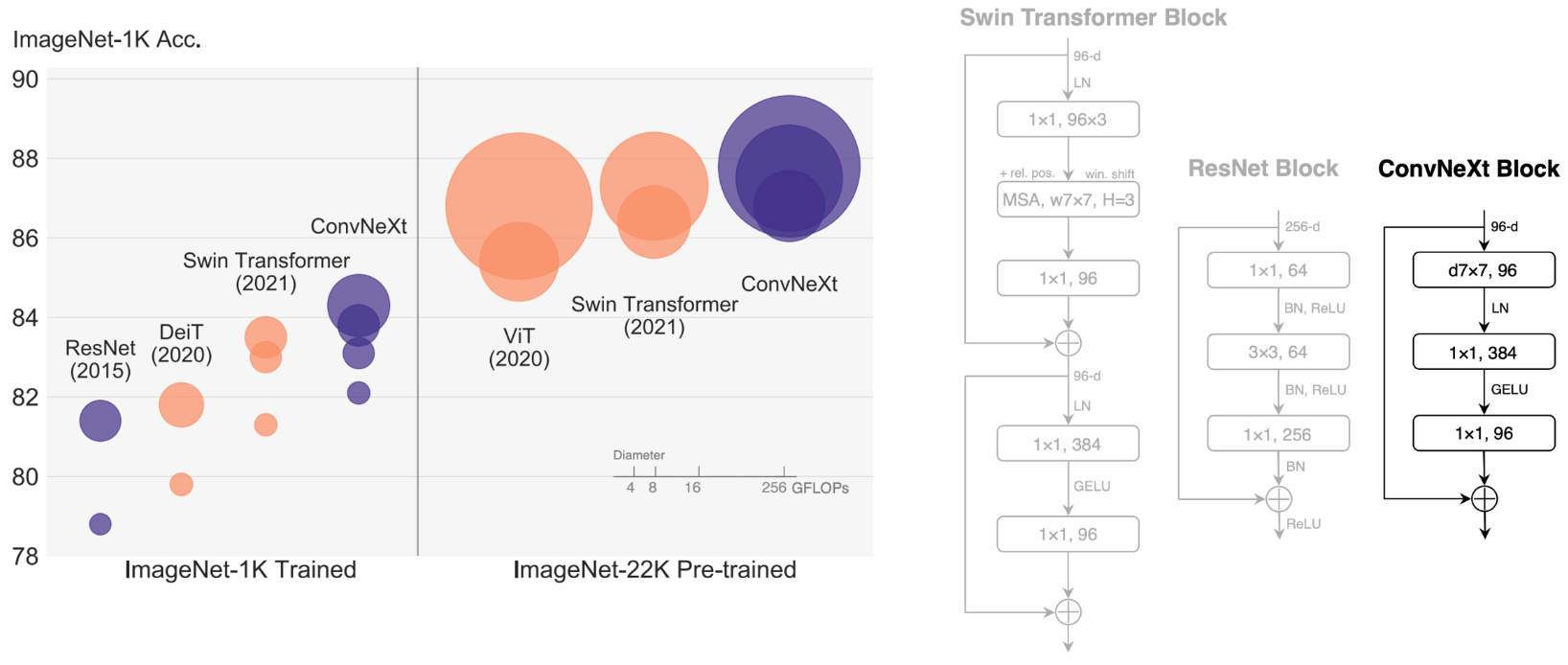
이미지 분류 프로젝트의 시작은 적합한 모델을 선정하는 과정이다. 딥러닝 기술이 발전하면서 모델 종류보다는 학습 데이터의 품질과 양이 모델 성능에 더 중요한 영향을 끼친다는 점이 명확해졌다. 이번 프로젝트는 가볍고 성능이 우수한 모델이 필요했기에 ConvNext를 선택했다. ConvNext는 효율성을 극대화한 순수 컨볼루션 신경망으로, 최신 모델의 성능을 따라잡으면서도 구조가 단순해 빠르고 효과적인 학습이 가능했다.
2. 학습 및 평가 데이터 구축
학습 및 평가 데이터를 구축하는 첫 단계로, 기존에 공개된 퍼블릭 데이터셋을 확인해보는 것이 좋다. 퍼블릭 데이터셋은 학습 데이터를 준비하는 시간을 단축하는 데 큰 도움이 될 수 있기 때문이다. 이번 프로젝트에서는 약 10개의 카테고리로 이미지를 분류하는 작업이 필요했는데, 일반적인 이미지 데이터는 많지만, 특정 조건을 충족하는 데이터를 찾는 것은 쉽지 않았다.
고품질 데이터셋을 구축하기 위해서는 분류 기준을 충족하면서도 최종 서비스 데이터와 유사한 분포를 갖추는 것이 중요하다. 예를 들어, 해외 이미지만 포함된 데이터셋으로 학습하면, 실제 서비스에 활용될 국내 데이터에서 정확도가 떨어질 가능성이 크다. 이를 해결하기 위해, 프로젝트 특성에 맞는 이미지를 직접 수집하고 분류하는 작업이 필요했다.
이번 프로젝트에서는 약 20만 장의 이미지를 수집했으며, 이를 학습 및 평가용으로 사용하기 위해 분류 기준에 따라 데이터를 나누는 작업을 진행했다. 하지만 이렇게 많은 양의 데이터를 사람이 일일이 분류하는 데는 상당한 시간이 필요했다. 이를 보완하기 위해 자동화된 데이터 선분류 기법을 활용했다.
2.1 학습 데이터 선분류
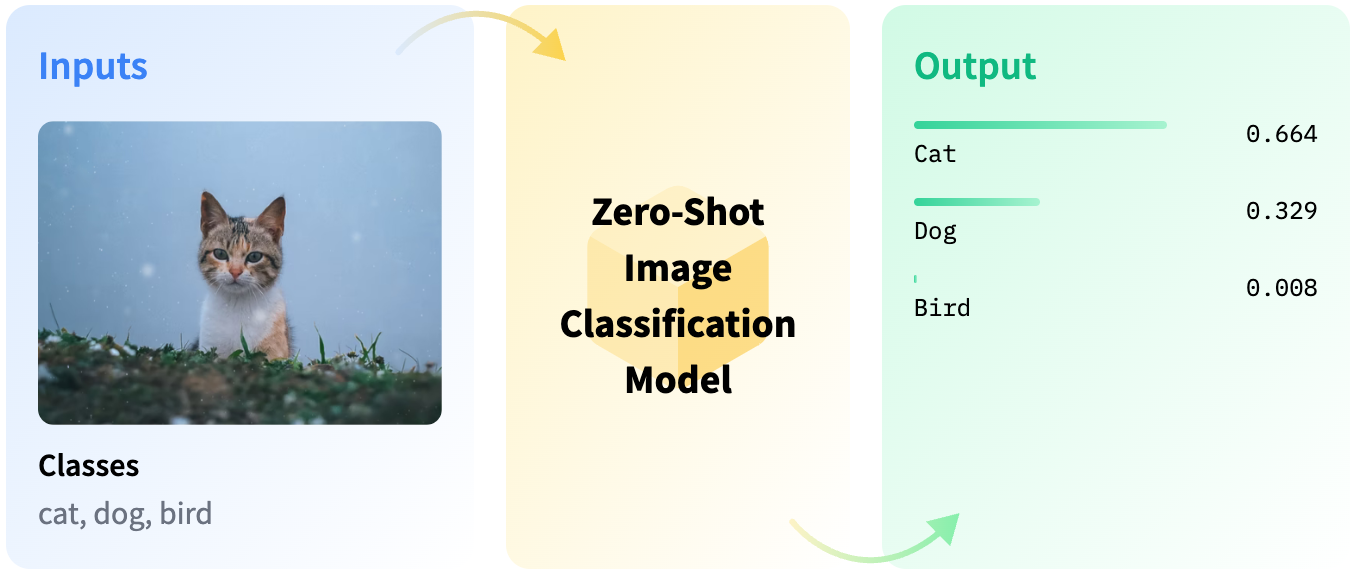
대량의 데이터를 효율적으로 분류하기 위해 Zero-shot 분류 기법을 활용했다. CLIP과 같은 멀티모달 모델을 사용하여, 이미지와 텍스트 간의 유사도를 기반으로 데이터를 자동 분류했다. 예를 들어, 특정 동작이 포함된 이미지나 물체의 특징을 설명하는 텍스트 쿼리를 입력하면, 이미지와 각 텍스트 쿼리 간의 상관성을 계산해 의사 라벨(Pseudo label)을 생성하는 방식이다.
Zero-shot 분류는 데이터를 자동화하는 데 유용하지만, 초기 결과에는 노이즈가 섞일 가능성이 크다. 이를 보완하기 위해 텍스트 쿼리를 더 구체화하고, 일부 샘플 데이터로 정확도를 테스트한 뒤 신뢰도 높은 데이터를 선별했다. 또한, 모델 출력의 유사도가 특정 Threshold 이상인 데이터만 선분류 데이터셋에 포함시켜 데이터 품질을 관리했다.
예를 들어, 텍스트 쿼리가 “특정 상황에서의 물체”와 같은 더 구체적인 설명을 포함하도록 개선했다. 이와 같은 방식으로 분류된 데이터는 일부 오류가 포함될 수 있으므로, 카테고리별로 데이터를 정리한 뒤 검수 과정을 거쳤다. 이렇게 선분류된 데이터는 최종 학습 데이터의 약 40%를 차지했으며, 초기 모델 학습과 실험에 활용되었다.
2.2 테스트 데이터셋 구축
테스트 데이터셋은 모델 성능 평가에 있어 매우 중요한 역할을 한다. 단순히 학습 데이터의 일부를 나누는 방식으로는 충분하지 않으며, 테스트 데이터는 학습 데이터와 다른 상황이나 환경을 반영할 수 있어야 한다.
예를 들어, 특정 작업 환경에서 촬영된 이미지, 다양한 조명 조건, 혹은 다른 각도에서 찍힌 이미지 등을 포함해 데이터의 다양성을 확보하는 것이 중요하다. 이렇게 구성된 테스트 데이터셋은 모델의 일반화 성능을 평가하는 데 필수적이며, 데이터 편향을 방지하는 데 도움을 준다.
테스트 데이터가 특정 유형에만 치우치면 일부 카테고리의 성능이 과도하게 높거나 낮게 나올 수 있으며, 이는 모델의 약점을 제대로 파악하지 못하게 한다. 따라서 다양한 사례를 포괄적으로 포함하는 테스트 데이터셋을 구성하는 것이 필요하다.
3. 모델 학습 및 평가
레이블링 작업이 진행되는 동안, 선분류된 데이터를 활용해 이미지 분류 모델을 학습했다. 이번 프로젝트에서는 ConvNext 모델을 선택해 학습을 진행했으며, Zero-shot 분류를 통해 구축한 데이터만으로 초기 학습을 완료했다. 이 과정에서 모델의 Mean accuracy는 약 90%에 도달했지만, 카테고리가 비교적 단순한 작업임을 고려했을 때 다소 부족한 성능으로 판단되었다.
모델의 성능을 자세히 분석하기 위해 Confusion matrix를 활용했다. Mean accuracy만으로는 모델이 어떤 데이터를 잘못 분류하는지 알기 어렵지만, Confusion matrix는 각 카테고리별로 모델의 오분류 경향을 시각적으로 보여준다. 이를 통해 데이터 분포가 넓거나 다양한 특성을 가진 특정 카테고리에서 오류가 더 자주 발생한다는 점을 확인할 수 있었다.
3.1 데이터 다양성과 모델 성능 개선
분류 성능이 낮은 카테고리의 데이터를 보강하기 위해, 보다 다양한 특성을 가진 이미지를 추가로 수집하고 레이블링 작업을 진행했다. 데이터가 다소 복잡하거나 분포가 넓은 카테고리의 경우, 모델이 특정 특징을 효과적으로 학습하지 못할 가능성이 크기 때문에 데이터를 세분화하고 구체화하는 과정을 거쳤다. 이러한 노력 덕분에 모델의 성능을 향상시킬 수 있었다.
모델의 학습 결과를 종합적으로 살펴본 결과, 대부분의 분류 오류는 여러 카테고리의 특성이 혼재된 데이터에서 발생했다. 이를 해결하기 위해 후처리 기법을 적용해 불확실성이 높은 데이터를 보완했다.
3.2 모델 비교와 학습 효율성
학습 효율성을 확인하기 위해, ConvNext 모델과 ResNet 모델을 비교하는 실험을 진행했다. 두 모델의 최종 성능은 유사했지만, 학습 과정에서 ConvNext 모델이 훨씬 빠르게 수렴하고 안정적인 Loss 곡선을 보여줬다.
Training Loss와 Test accuracy를 시각적으로 비교한 결과, ConvNext 모델이 더 낮은 Loss 값으로 빠르게 수렴했으며, Test accuracy 또한 초반 학습 단계에서 ResNet보다 더 빠르게 상승했다. ConvNext 모델의 최신 구조적 장점 덕분에 학습 속도와 효율성이 향상된 것으로 분석된다.
최종 모델을 선정할 때는 단순히 최종 성능뿐만 아니라 학습 시간과 효율성도 중요한 요소로 고려해야 한다. 이러한 비교 실험은 모델 선정 과정에서 중요한 참고 자료가 된다.
3.3 EMA(Exponential Moving Average) 적용
모델 학습의 안정성과 일반화 성능을 향상시키기 위해 EMA(Exponential Moving Average) 기법도 실험적으로 적용해보았다. EMA는 모델의 파라미터 업데이트 시, 과거 파라미터를 일정 비율로 반영하여 변화를 완화시키는 방식으로, 급격한 변동을 줄이고 모델의 예측 일관성을 높이는 데 효과적이다.
실험 결과, EMA를 적용한 모델은 학습이 더 빠르게 수렴했으며, 성능의 변동성이 줄어들어 더욱 안정적인 결과를 보였다. 특히 데이터 분포가 다양한 환경에서도 견고한 성능을 보여, 이미지 분류 모델 개발에서 EMA 기법의 유용성을 확인할 수 있었다.
3.4 OOD (Out-of-Distribution) 필터링
모델이 학습하지 않은 데이터나 학습 데이터와 다른 분포를 가진 데이터를 처리하기 위해 OOD(Out-of-Distribution) 필터링 기법을 적용했다. 가장 간단한 방법으로, 모델의 Softmax 출력값을 기반으로 Confidence score를 계산하고 특정 Threshold를 초과하는 데이터를 OOD로 판단했다.
단, Softmax 출력은 딥러닝 모델의 불확실성을 정확히 반영하지 못할 수 있으므로, Temperature scaling을 활용해 Confidence score를 조정했다. 실험에서는 다양한 Temperature와 Threshold 값을 테스트하여 최적의 설정을 찾았다.
Threshold가 높아질수록 특정 데이터를 OOD로 분류할 가능성이 커지지만, 이와 동시에 전체 모델의 정확도는 감소할 수 있었다. 이러한 실험 결과를 바탕으로 적절한 Threshold를 설정해, 모델 성능을 극대화하면서도 불필요한 데이터를 효과적으로 필터링할 수 있었다.
이번 프로젝트는 Zero-shot 분류와 OOD 필터링을 활용한 데이터 처리 및 모델 학습 전략이 개발 효율성을 크게 향상시킬 수 있음을 보여주었다. 이러한 기법들은 단순히 학습 데이터를 준비하거나 모델을 개발하는 데 그치지 않고, 전체적인 개발 과정을 최적화하는 데 중요한 역할을 한다.
특히, 서비스에 활용 가능한 딥러닝 모델을 개발하기 위해서는 모델의 학습 성능뿐만 아니라, 데이터 처리, 전후처리 기능, 그리고 모델의 신뢰도와 안정성을 고도화하는 다방면의 접근이 필요하다.
딥러닝 기술이 발전함에 따라 데이터를 효율적으로 활용하고 실제 사용 사례에 적합한 모델을 만드는 전략이 점점 더 중요해지고 있다.